- 1. Introduction, Background, and Motivation
- 2. Review of Logic with Sets, Relations, and Operators
- 2.1. Formulas without quantifiers
- 2.2. Terms: integers and term operators that take integer inputs
- 2.3. Formulas: relational operators and predicates dealing with integers
- 2.4. Terms: finite sets of integers, term operators that take set inputs, and set comprehensions
- 2.5. Formulas: quantifiers over finite sets of integers
- 2.6. Formulas: predicates dealing with finite sets of integers
- 2.7. Terms: set products and binary relations
- 2.8. Formulas: predicates dealing with relations
- 2.9. Terms: set quotients and quotient maps
- 2.10. Assignment #1: Logic, Integers, Sets, and Relations
- 3. Modular Arithmetic
- 3.1. Terms: congruence classes in ℤ/mℤ, term operators, and relations
- 3.2. Algebra of congruence classes
- 3.3. Multiplication by a congruence class as a permutation
- 3.4. Generating random numbers
- 3.5. Greatest common divisor and related facts
- 3.6. Generating prime numbers
- 3.7. Detecting probable prime numbers
- 3.8. Assignment #2: Modular Arithmetic, Random Numbers, and Primes
- 3.9. Multiplicative inverses
- 3.10. Chinese remainder theorem (CRT) and applications
- 3.11. Solving systems of equations with CRT solutions using multiplicative inverses
- 3.12. More practice with CRT
- 3.13. Euler's totient function, Euler's theorem, and applications
- 3.14. Assignment #3: Multiplicative Inverses, CRT, and Efficient Computation
- Review #1: Properties, Algorithms, and Applications of Modular Arithmetic
- 4. Computational Complexity of Modular Arithmetic Algorithms
- 5. Algebraic Structures
- 5.1. Permutations
- 5.2. Isomorphisms: Equivalence of Algebraic Structures
- 5.3. Generators of Algebraic Structures
- 5.4. Assignment #5: Algebraic Structures and Isomorphisms
- 5.5. Isomorphisms and Linear Equations of Congruence Classes
- 5.6. Isomorphisms and the Chinese Remainder Theorem
- 5.7. Abstract Algebraic Structures and Axioms
- 5.8. Subgroups and the Hidden Subgroup Problem
- 5.9. Structural Induction and Direct Product of Algebraic Structures
- 5.10. Assignment #6: Generalized CRT, Data Structures, and More Isomorphisms
- Review #2: Algebraic Structures and their Properties
- Appendix A. Using gsubmit
- Appendix B. Python
[link] 1. Introduction, Background, and Motivation
[link] 1.1. Overview
When many real-world problems are addressed or solved mathematically and computationally, the details of those problems are abstracted away until they can be represented directly as idealized mathematical structures (e.g., numbers, sets, trees, graphs, matrices, and so on). In this course, we will study a collection of such idealized mathematical objects: integers, groups, residues, and several others. We will see how these structures and their properties can be used for implementing useful computational solutions to problems such as random number generation, prime number generation, error correction, trusted and distributed storage, secure communication, and others.
In covering the material for this course, we will use the standard language and conventions for discussing these mathematical structures that have been developed by the community of mathematicians over the course of history. You will need to become familiar with these conventions in order to find, identify, and use the structures and techniques that have already been developed for representing and solving certain computational problems. At the same time, we will also learn how modern programming languages and programming paradigms can be used to implement these structures and algorithms both accessibly and efficiently.
The development and application of mathematics involves abstraction. A problem can be viewed at multiple levels of abstraction, and in developing mathematics humans have adopted a variety of techniques that allow them to successfully employ abstraction to study natural phenomena and solve problems.
| symbolic | abstract meaning | concrete meaning in application domain |
| 2 + 3 | 5 | five objects |
| {(1, 2), (1, 3)} | acyclic graph | file system |
| {(1, 2), (2, 3), (3, 1)} | graph with cycle | network |
| {(0,1), (1,2), (2,0)} | permutation | random number sequence |
The above illustrates the different levels of abstraction that may exist for a given problem. We employ a language of symbols to denote certain abstract structures, which may correspond to actual structures in the world. A string of symbols corresponds to a particular abstract object. Notice that the actual object being modelled and the abstract structure behave the same way, and that this behavior implies certain rules about how we can manipulate the symbols without changing the object that they name. For example, we can represent the same graph using the two strings of symbols "{(1,2), (2,3), (3,1)}" and "{(1,2), (2,3), (3,1)}", or the same number of objects using "2 + 3", "3 + 2", "1 + 4", and so on.
In this course, we will begin to reviewing the terminology and concepts of logic, integer arithmetic, and set theory, which we will use throughout the course. We will then show that the algebraic properties of the integers also apply to congruence classes of integers (i.e., the properties of modular arithmetic operations), and we will derive and utilize theorems that have useful computer science applications (such as for generating random numbers and creating cryptographic protocols). We will then go further and show that some of the algebraic properties that hold in integer and modular arithmetic can also apply to any data structure, and we will study how to recognize and take advantage of these properties.
[link] 1.2. Informal motivating example: random number generation
Let us informally consider the problem of generating a sequence of random positive integers. Random number generators are needed in many situations and applications, including:- generating unique identifiers for database records, objects, etc.;
- generating a one-time pad for a simple encryption scheme;
- generating public and private keys for more sophisticated encryption and signature schemes;
- simulation and approximation methods that employ random sampling (Monte-Carlo, and so on).
- n0 = a number in the range (inclusive) 0 to 5;
- ni = (2 ⋅ ni-1 + 1) mod 6.
- n0 = an initial seed integer 104 > n ≥ 103;
- ni = only the last four digits of ni-12.
One way to model a random number generation process is to view it is a permutation. In fact, there is more than one way to view the process as a permutation. We could simply count up from 0 to m and apply the same permutation to each 0 ≤ n ≤ m in order to produce the nth random number in the sequence. Is there an efficient way (i.e., using no more memory than O(log m)) to compute a random number from each n such that a number never repeats?
In this course we will learn about a variety of mathematical structures and their properties that will allow us to precisely specify the above problem and others like it, to identify what solutions are appropriate for such a problem, and to implement these solutions correctly and, where necessary, efficiently.
[link] 2. Review of Logic with Sets, Relations, and Operators
In this section, we will review several abstract structures and associated properties (and the symbolic language used to represent them) that you should have already encountered in past courses. Simultaneously, we will review one way in which these structures can be implemented and manipulated within the modern programming language Python. As with most human languages that have developed organically over time, mathematics has a rich and often redundant vocabulary. We introduce many terms in this section that we will use consistently in this course. However, keep in mind that there are often other synonyms within mathematics and computer science for these structures.[link] 2.1. Formulas without quantifiers
| formula | meaning | example of one possible Python representation |
| true | always true | True |
| false | always false | False
|
| f1 and f2 | only true if both f1 and f2 are true | True and False |
| f1 or f2 | true if f1 or f2 (or both) are true | True or (False and True) |
| f1 implies f2 |
|
False <= True |
| f1 iff f2 |
|
True == False |
| ¬ f | true if f is false | not (True or (False and True)) |
| ( f ) | true if f is true | (True and (not (False)) |
| predicate example | depends on the definition of the predicate |
isPrime(7) |
The following table may help with gaining a good intuition for the meaning of the implies operator.
| meaning of left-hand side (premise) |
meaning of right-hand side (conclusion) |
meaning of entire formula |
comments |
| true | true | true | if the premise is true and the conclusion is true, the claim of implication is true; thus, the whole formula is true |
| true | false | false | if the premise is true but the conclusion is false, the conclusion is not implied by the premise, so the claim of implication is false; thus, the formula is false |
| false | true | true | if the conclusion is true on its own, it doesn't matter that the premise is false, because anything implies an independently true conclusion; thus, the claim of implication is true, and so is the entire formula |
| false | false | true | if we assume that a false premise is true, then "false" itself is "true"; in other words, false implies itself, so the formula is true |
|
| the sun is visible | it is daytime | meaning | interpretation |
| true | true | true | a sunny day |
| true | false | false | |
| false | true | true | a cloudy day |
| false | false | true | nighttime |
|
[link] 2.2. Terms: integers and term operators that take integer inputs
| term | what it represents | example of one possible Python representation |
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| z1 + z2 | the integer sum of z1 and z2 | 3 + 4
|
| z1 − z2 | the integer difference of z1 and z2 | (1 + 2) - 4
|
| z1 ⋅ z2 | the integer product of z1 and z2 | 3 * 5
|
| z1 mod z2 | the remainder of the integer quotient z1 / z2 z1 - ⌊ z1/z2 ⌋ ⋅ z2 |
17 % 5
|
| z1z2 | product of z2 instances of z1 | 2**3pow(2,3)
|
[link] 2.3. Formulas: relational operators and predicates dealing with integers
| formula | what it represents | example of one possible Python representation |
| z1 = z2 | true if z1 and z2 have the same meaning; false otherwise |
1 == 2 |
| z1 < z2 | true if z1 is less than z2; false otherwise |
4 < 3 |
| z1 > z2 | true if z1 is greater than z2; false otherwise |
4 > 3 |
| z1 ≤ z2 | true if z1 is less than or equal to z2; false otherwise |
4 <= 3 |
| z1 ≥ z2 | true if z1 is greater than or equal to z2; false otherwise |
4 >= 3 |
| z1 ≠ z2 | true if z1 is not equal to z2; false otherwise |
4 != 3 |
| predicate definition | example of one possible Python representation |
| P(x) iff x > 0 and x < 2 | def P(x): return x > 0 and x < 2 |
| Q(x) iff x > 3 | Q = lambda x: x > 3 |
| formula | what it represents | example of one possible Python representation |
| P(1) | true | P(1) |
| P(1) or P(2) | true | P(1) or P(2)
|
| Q(1) and P(1) | false | Q(1) and Q(1)
|
| formula | what it represents |
| x | y |
|
| y is prime |
|
def divides(x,y):
return y % x == 0 # The remainder of y/x is 0.
def prime(y):
for x in range(2,y):
if divides(x,y):
return False
return True
[link] 2.4. Terms: finite sets of integers, term operators that take set inputs, and set comprehensions
| term | what it represents | example of one possible Python representation |
| ∅ | a set with no elements in it | set() |
| {1,2,3} | {1,2,3} | {1,2,3} |
| {2,..,5} | {2,3,4,5} | set(range(2,6)) |
| { x | x ∈ {1,2,3,4,5,6}, x > 3 } | {4,5,6} | {x for x in {1,2,3,4,5,6} if x > 3}
|
| |{1,2,3,4}| | 4 | len({1,2,3,4})
|
| term | what it represents | example of one possible Python representation |
| S1 ∪ S2 | {z | z ∈ ℤ, z ∈ S1 or z ∈ S2} | {1,2,3}.union({4,5}){1,2,3} | {4,5} |
| S1 ∩ S2 | {z | z ∈ ℤ, z ∈ S1 and z ∈ S2} | {1,2,3}.intersection({2,3,5}){1,2,3} & {2,3,5} |
| |S| | the number of elements in S | len({1,2,3}) |
| term | what it represents |
| ℕ | {0, 1, 2, ...} |
| ℤ | {..., -2, -1, 0, 1, 2, ...} |
[link] 2.5. Formulas: quantifiers over finite sets of integers
def forall(S, P):
for x in S:
if not P(x):
return False
return True
def exists(S, P):
for x in S:
if P(x):
return True
return False
subset() operation on sets.
def forall(X, P):
S = {x for x in X if P(x)}
return len(S) == len(X)
def exists(X, P):
S = {x for x in X if P(x)}
return len(S) > 0
def subset(X,Y):
return forall(X, lambda x: x in Y)
| formula | what it represents | example of one possible Python representation |
| 1 ∈ {1,2,3} | true | 1 in {1,2,3} |
| 4 ∈ {1,2,3} | false | 4 in {1,2,3} |
| ∀ x ∈ {1,2,3}, x > 0 and x < 4 | true | forall({1,2,3}, lambda x: x > 0 and x < 4) |
| ∃ x ∈ {1,2,3}, x < 1 and x > 3 | false | exists({1,2,3}, lambda x: x < 1 or x > 3) |
| ∀ x ∈ ∅, f | true | |
| ∃ x ∈ ∅, f | false |
| iff |
| |||
| iff |
|
-
All the elements of a set X satisfy the predicate P.
# We provide two equivalent implementations.
def all(X, P):
return forall(X, P)
def all(X, P):
S = {x for x in X if P(x)}
return len(S) == len(X)
-
None of the elements of a set X satisfy the predicate P.
# We provide two equivalent implementations.
def none(X, P):
return forall(X, lambda x: not P(x))
def none(X, P):
S = {x for x in X if P(x)}
return len(S) == 0
-
At most one of the elements of a set X satisfy the predicate P.
def atMostOne(X, P):
S = {x for x in X if P(x)}
return len(S) <= 1
-
At least one of the elements of a set X satisfy the predicate P.
# We provide two equivalent implementations.
def atLeastOne(X, P):
return exists(X, P)
def atLeastOne(X, P):
S = {x for x in X if P(x)}
return len(S) >= 1
def prime(p):
return p > 1 and forall(set(range(2, p)), lambda n: p % n != 0)
[link] 2.6. Formulas: predicates dealing with finite sets of integers
| formula | what it represents | example of one possible Python representation |
| 3 ∈ {1,2,3} | true | 3 in {1,2,3} |
| {1,2} ⊂ {1,2,3} | true | subset({1,2}, {1,2,3}) |
| {4,5} ⊂ {1,2,3} | false | subset({4,5}, {1,2,3}) |
| formula | what it represents |
| z ∈ S | true if z is an element of S; false otherwise |
| S1 ⊂ S2 | ∀ z ∈ S1, z ∈ S2 |
| S1 = S2 | S1 ⊂ S2 and S2 ⊂ S1 |
[link] 2.7. Terms: set products and binary relations
| term | what it represents | example of one possible Python representation |
| {1,2} × {5,6,7} | {(1,5),(1,6),(1,7),(2,5),(2,6),(2,7)} | { (x,y) for x in {1,2} for y in {4,5,6,7} } |
[link] 2.8. Formulas: predicates dealing with relations
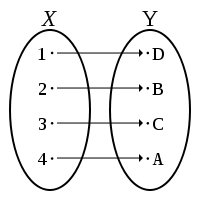
There are several common properties that relations may possess.| predicate | definition | graphical example |
| X × Y is the set product of X and Y | X × Y = { (x,y) | x ∈ X, y ∈ Y } | |
| R is a relation between X and Y | R ⊂ X × Y | 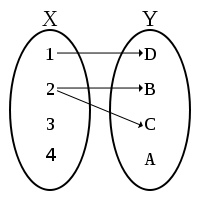 |
| R is a function from X to Y R is a (many-to-one) map from X to Y |
R is a relation between X and Y and ∀ x ∈ X, there is at most one y ∈ Y s.t. (x,y) ∈ R |
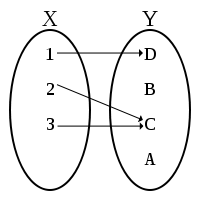 |
| R is an injection from X to Y |
R is a relation between X and Y and ∀ y ∈ Y, there is at most one x ∈ X s.t. (x,y) ∈ R |
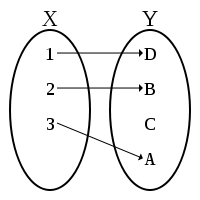 |
| R is a surjection from X to Y |
R is a relation between X and Y and ∀ y ∈ Y, there is at least one x ∈ X s.t. (x,y) ∈ R |
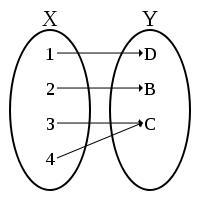 |
| R is a bijection between X and Y | R is an injection from X and Y and R is a surjection from X and Y |
 |
| R is a permutation on X | R ⊂ X × X and R is a bijection between X and X |
|
| R is a reflexive relation on X | R ⊂ X × X and ∀ x ∈ X, (x,x) ∈ R |
|
| R is a symmetric relation on X | R ⊂ X × X and ∀ x ∈ X, ∀ y ∈ X, (x,y) ∈ R implies (y,x) ∈ R |
|
| R is a transitive relation on X | R ⊂ X × X and ∀ x ∈ X, ∀ y ∈ X, ∀ z ∈ X, ((x,y) ∈ R and (y,z) ∈ R) implies (x,z) ∈ R |
|
| R is an equivalence relation on X R is a congruence relation on X |
R ⊂ X × X and R is a reflexive relation on X and R is a symmetric relation on X and R is a transitive relation on X |
evens = { 2 * x for x in set(range(0,51)) }
evens = { x for x in set(range(0,101)) if x % 2 == 0 }
X and Y.
def product(X, Y):
return { (x,y) for x in X for y in Y }
def leq(S):
return { (x, y) for x in S for y in S if x <= y }
R is a relation over a set X.
# Using our definition of subset().
def relation(R, X):
return subset(R, product(X, X))
# Using the built-in set implementation.
def relation(R, X):
return R.issubset(product(X, X))
|
R and a set X and determines whether that relation is asymmetric? Recall that we can represent the implication logical operator using the Python operator <=.
def isAsymmetric(X, R):
return relation(R,X) and forall(X, lambda a: forall(X, lambda b: ((a,b) in R) <= (not ((b,a) in R))))
[link] 2.9. Terms: set quotients and quotient maps
Given an equivalence relation on a set, we can partition that set into a collection of distinct subsets, called equivalence classes, such that all the elements of each subset are equivalent to one another.
| = |
|
def quotient(X,R):
return {frozenset({y for y in X if (x,y) in R}) for x in X}
>>> quotient({1,2,3,4}, {(1,1),(2,2),(3,3),(2,3),(3,2),(4,4)})
{frozenset({4}), frozenset({2, 3}), frozenset({1})}
def quotientMap(X,R):
return {(x, frozenset({y for y in X if (x,y) in R})) for x in X}
| = |
|
{'Alice', 'Bob', 'Carl', 'Dan', and 'Eve'}:
R = {\
('Alice', 'Alice'), ('Bob', 'Bob'), ('Carl', 'Carl'), ('Dan', 'Dan'), ('Eve', 'Eve'),\
('Alice', 'Carl'), ('Carl', 'Alice'), ('Dan', 'Eve'), ('Eve', 'Dan')\
}
families = quotient({'Alice', 'Bob', 'Carl', 'Dan', 'Eve'}, R)
[link] 2.10. Assignment #1: Logic, Integers, Sets, and Relations
hw1/hw1.py. Please follow the gsubmit directions.
Your file may not import any modules or employ any external library functions associated with integers and sets (unless the problem statement explicitly permits this). You may include in your module any function that is defined in the lecture notes.
Solutions to each of the programming problem parts below should fit on 1-3 lines. You will be graded on the correctness, concision, and mathematical legibility of your code. The different problems and problem parts rely on the lecture notes and on each other; carefully consider whether you can use functions from the lecture notes, or functions you define in one part within subsequent parts.
-
Implement a Python function
cube(n)that takes a single positive integer argumentnand returnsTrueif and only ifnis a perfect cube (i.e., there exists an integerksuch thatk3 =n). You cannot use loops, and you must useexists()to receive credit. Efficiency is not important.
>>> cube(27)
True
>>> cube(12)
False
-
Implement a Python function
properPrimeFactors(n)that takes a single positive integer argumentnand returns a finite set of integers containing all the prime proper factors of that number.
>>> properPrimeFactors(9)
{3}
>>> properPrimeFactors(14)
{2,7}
-
Implement a Python function
shared(S)that takes any finite set of positive integersSand returns a relation overSin which any two numbers inSthat share at least one prime proper factor are related. If a number has no proper prime factors, then it shares no proper prime factors with any other number (including itself).
>>> shared({4,5,6,7,8,9})
{(4,4), (4,6), (4,8), (6,4), (6,6), (6,8),
(6,9), (8,4), (8,6), (8,8), (9,6), (9,9)}
>>> shared({9,14,28})
{(9,9), (14,14), (14,28), (28,14), (28,28)}
>>> shared({11,12})
{(12,12)}
-
Determine which of the three properties of an equivalence relation (reflexivity, symmetry, and transitivity) always apply to any result of
shared()(assuming its input is a finite set of positive integers). Define three veriables in your code; each will represent a counterexample input (if it exists) that leads to an output that does not have the corresponding property:If a property always applies to any output of
reflexive = ?
symmetric = ?
transitive = ?
shared(), simply assignNoneto the corresponding variable. If a property does not apply to all outputs ofshared(), assign an input set to the corresponding variable that returns an output relation that does not satisfy that property. For example, if we were doing the same thing for the property of asymmetry, we would choose a value forasymmetricsuch that:
>>> isAsymmetric(asymmetric, shared(asymmetric))
False
-
Implement a Python function
-
Solve the following problems involving relations. Recall that using Python, we are representing relations as sets of tuples (i.e., pairs such as
(1,2)).-
Implement a function
isSymmetric()that takes as its input two arguments: a setXand a relationR. The function should returnTrueif the relationRis a symmetric relation onX, and it should returnFalseotherwise.
isSymmetric({1,2}, {(1,1), (2,2), (2,1), (1,2)}) == True
isSymmetric({1,2,3}, {(1,2), (2,1), (3,3)}) == True
isSymmetric({'a','b','c'}, {('a','a'), ('b','b'), ('a','c')}) == False
-
Implement a function
isTransitive()that takes as its input two arguments: a setXand a relationR. The function should returnTrueif the relationRis a transitive relation onX, and it should returnFalseotherwise. -
Implement a function
isEquivalence()that takes as its input two arguments: a setXand a relationR. The function should returnTrueif the relationRis an equivalence relation onX, and it should returnFalseotherwise. Hint: read the notes in this section carefully and reuse functions that have already been defined.
isEquivalence({1,2,3}, {(1,1), (2,2), (3,3)}) == True
isEquivalence({1,2,3}, {(1,2), (2,1), (3,3)}) == False
isEquivalence({1,2}, {(1,1), (2,2), (1,2), (2,1)}) == True
isEquivalence({0,3,6}, {(0,3), (3,6), (0,6), (3,0), (6,3), (6,0)}) == False
-
Implement a function
-
You should include the following definition in your module:
Solve the following problems by defining appropriate relations.
def quotient(X, R):
return {frozenset({y for y in X if (x,y) in R}) for x in X}
-
Include the following definitions in your code:
Define the variable
X1 = {"a","b","c","d","e"}
R1 = ?
R1above so thatR1is an equivalence relation overX1, and so that the following will evaluate toTrue:
>>> isEquivalence(X1,R1)
True
>>> quotient(X1,R1) == {frozenset({"a", "c"}), frozenset({"b", "d"}), frozenset({"e"})}
True
-
Include the following definitions in your code:
Define the variable
X2 = {0,1,2,3,4,5,6,7,8,9}
R2 = ?
R2above so thatR2is an equivalence relation overX2, and so that the following will evaluate toTrue:
>>> isEquivalence(X2,R2)
True
>>> quotient(X2,R2) == {frozenset({0,4,8}), frozenset({1,5,9}), frozenset({2,6}), frozenset({3,7})}
True
-
Include the following definitions in your code:
Define the variable
X3 = set(range(-25,26))
R3 = ?
R3above so thatR3is an equivalence relation overX3, and so that the following will evaluate toTrue:You must use a set comprehension to define
>>> isEquivalence(X3,R3)
True
>>> quotient(X3,R3) == {frozenset(range(-25,0)), frozenset({0}), frozenset(range(1,26))}
True
R3. Solutions that use an explicitly defined set will receive no credit.
-
Include the following definitions in your code:
[link] 3. Modular Arithmetic
Modular arithmetic can be viewed as a variant of integer arithmetic in which we introduce a congruence (or equivalance) relation on the integers and redefine the integer term operators so that they are defined on these congruence (or equivalance) classes.[link] 3.1. Terms: congruence classes in ℤ/mℤ, term operators, and relations
| = |
|
| = |
|
| = |
|
| ∈ |
| |||
| ∈ |
|
| = |
| |||
| = |
| |||
| = |
|
| term | what it represents |
| z z mod m z + mℤ |
{z + (a ⋅ m) | a ∈ ℤ} |
| c1 + c2 | {(x + y) | x ∈ c1, y ∈ c2} |
| c1 − c2 | {(x − y) | x ∈ c1, y ∈ c2} |
| c1 ⋅ c2 | {(x ⋅ y) | x ∈ c1, y ∈ c2} |
| cz | c ⋅ ... ⋅ c |
| c! | c ⋅ (c-1) ⋅ (c-2) ⋅ ... ⋅ 1 |
| formula | what it represents |
| c1 ≡ c2 | true only if c1 ⊂ c2 and c2 ⊂ c1, i.e., set equality applied to the congruence classes c1 and c2; false otherwise |
[link] 3.2. Algebra of congruence classes
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
|
|
| ≡ |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| ≡ |
| ||||
| ≡ |
|
| property | definition |
| ℤ/mℤ is closed under + | ∀ x,y ∈ ℤ/mℤ, x + y ∈ ℤ/mℤ |
| + is commutative on ℤ/mℤ | ∀ x,y ∈ ℤ/mℤ, x + y ≡ y + x |
| + is associative on ℤ/mℤ | ∀ x,y,z ∈ ℤ/mℤ, (x + y) + z ≡ x + (y + z) |
| + has a (left and right) identity 0 in ℤ/mℤ | ∀ x ∈ ℤ/mℤ, 0 + x ≡ x and x + 0 ≡ x |
| ℤ/mℤ has inverses with respect to + | ∀ x ∈ ℤ/mℤ, (m - x) + x ≡ 0 |
| ℤ/mℤ is closed under ⋅ | ∀ x,y ∈ ℤ/mℤ, x ⋅ y ∈ ℤ/mℤ |
| ⋅ is commutative on ℤ/mℤ | ∀ x,y ∈ ℤ/mℤ, x ⋅ y ≡ y ⋅ x |
| + is associative on ℤ/mℤ | ∀ x,y,z ∈ ℤ/mℤ, (x ⋅ y) ⋅ z ≡ x ⋅ (y ⋅ z) |
| + has a (left and right) identity 1 in ℤ/mℤ | ∀ x ∈ ℤ/mℤ, 1 ⋅ x ≡ x and x ⋅ 1 ≡ x |
| ⋅ distributes across + in ℤ/mℤ | ∀ x,y,z ∈ ℤ/mℤ, x ⋅ (y + z) ≡ (x ⋅ y) + (x ⋅ z) |
- it is often possible to find the unique solution to an equation over ℤ/mℤ, while equations over ℤ involving the modulus operation may have infinitely many solutions;
- the set ℤ/mℤ is finite, so there is always a finite number of possible solutions to test, even if this is very inefficient, while equations over the integers involving modulus have an infinite range of possible solutions to test;
- the set ℤ/mℤ is a group and is a prototypical example of an algebraic structure, and gaining experience with algebraic structures is one of the purposes of this course, as algebraic structures are ubiquitous in computer science and its areas of application.
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| = |
| |||
| = |
| |||
| ≡ |
|
| = |
| |||
| = |
| |||
| = |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| | |
| |||
| = |
| |||
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| = |
| |||
| = |
| |||
| ∈ |
| |||
| | |
|
| | |
| |||
| ∈ |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
|
Because c|a, it must be that a/c ∈ ℤ. But then we have that:
|
We can show this as follows:
| ≡ |
| |||
| | |
| |||
| | |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ∤ |
| |||
| ≢ |
| |||
| ∤ |
| |||
| ≢ |
|
We can derive the above fact by using the following steps:
| ≡ |
| |||
| ≡ |
| |||
| = |
| |||
| = |
| |||
| | |
|
| | |
| |||
| = |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
| = |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
[link] 3.3. Multiplication by a congruence class as a permutation
| = |
|
| = |
| |||
| = |
|
| ≠ |
| |||
| = |
|
| = |
| |||
| = |
| |||
| = |
| |||
| | |
|
- because a < p, p does not divide a;
- because p > i - j > 0, p cannot divide (i − j).
| = |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
[link] 3.4. Generating random numbers
| = |
| |||
| = |
| |||
| = |
|
| = |
| |||
| = |
| |||
| = |
|
| = |
|
| = |
|
- the "state" of the algorithm is easy to store: it consists of a single congruence class in ℤ/pℤ, which can be represented using an integer;
- the sequence that is generated will contain exactly one instance of all the numbers in the chosen range {0,...,p-1};
- the sequence that is generated can, at least in some cases, be a non-trivial sequence that might appear "random".
We know this is true because in this case, R is a permutation, so it satisfies Requirement 1. Furthermore, element v1 = b, so v is never the trivial sequence. Thus, Requirement 2 is satisfied.
- inputs: upper bound (prime) p ∈ ℕ, seed a ∈ {0,...,p-1}, index i ∈ ∈ {0,...,p-1}
-
- return (a ⋅ i) mod p
- if a non-prime upper bound is needed, it would be necessary to scale down the results from the smallest prime number that is greater than the desired upper bound, and this would eliminate the bijective property of the generator (multiple indices might map to the same random number);
- where do we even find a prime p efficiently that is close to the desired upper bound?
[link] 3.5. Greatest common divisor and related facts
| = |
|
| = |
| |||
| = |
|
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
|
def gcd(x, y):
return max({z for z in range(0, min(x,y)) if x % z == 0 and y % z == 0})
|
{(x,y) for x in S for y in S if gcd(x,y) != 1}
| ≢ |
| |||
| ≢ |
|
The above can be proven by noticing that if gcd(a,m) = 1, then a does not divide m and m does not divide a. Notice that in this fact in which p was required to be prime, the fact that p is prime was not used in isolation; only the coprime relationship between p and a was required.
| < |
|
| ≤ |
| |||
| ≤ |
|
| > |
|
We can prove this fact by contradiction. Suppose there exists a factor z > 1 of m and m+1. In other words, gcd(m,m+1) > 1. Then we have that:
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
|
- inputs: positive integer m ∈ ℕ
-
- p := any number in {3,...,m-1}
- while p − 1 and m are not coprime
- p := p ⋅ gcd(p − 1, m)
- return p − 1
- inputs: upper bound m ∈ ℕ, index i ∈ {0,...,m-1}
-
- a := number in {2,...,m-1} s.t. a and m are coprime (always the same a for an m)
- return (a ⋅ i) mod m
- inputs: upper bound m ∈ ℕ, index i ∈ {0,...,m-1}
-
- b := number in {2,...,m-1} s.t. b and m are coprime
-
for possible powers k in the range 1 to the bit length of m
- a := a power bk of b that is as close as possible to ((4/7) ⋅ m)
- return (a ⋅ i) mod m
- Find gcd(18,42).
- Find gcd(21000, 2100).
- For a positive even integer a ∈ ℤ, find gcd(a/2, a - 1).
- Suppose that for some a ∈ ℤ/mℤ, the set {i ⋅ a mod m | i ∈ {1,...,m-1}} contains every number in the set {1,...,m-1}. What is gcd(a, m)?
| ≡ |
|
| ≡ |
|
| = |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
[link] 3.6. Generating prime numbers
Many applications require the generation of new primes. We have already seen a simple example in which generating new random sequences required prime numbers. Another important class of applications with this requirement are cryptographic schemes and protocols. In this section, we consider the problem of generating prime numbers, and in particular, random prime numbers in a particular range.- inputs: set of primes {p1 ,... , pn}
-
- n := p1 ⋅ ... ⋅ pn + 1
- F := factors of n
- return any element in F
| = |
| |||
| = |
| |||
- If P+1 is prime, then P > pi for all i ∈ {1,...,n}, so P+1 is a new prime.
- If P+1 is not prime, it cannot share any factors with P since gcd(P, P + 1) = 1, so no factors of P+1 are in the set {p1 ,... , pn}. But it must have factors, so any of these factors will be different from the primes in the input set {p1 ,... , pn}.
|
|
- inputs: d ∈ ℕ
-
-
do
- n := any number from {10d, ..., 10d+1-1}
- return n
-
do
| = |
| |||
| = |
| ||||
| = |
| ||||
| ≈ |
|
- inputs: d ∈ ℕ
-
-
do
- n := any number from {10d-1, ..., 10d-1}
- return n
-
do
[link] 3.7. Detecting probable prime numbers
In this subsection, we consider the problem of defining a very efficient algorithm to check whether a positive integer m ∈ ℕ is prime. In fact, the algorithm we consider will be detectors of some, but not all, composite numbers.| algorithm input | algorithm output | meaning | description |
| actually a composite number (this is not known at time of input) |
composite | the input is composite | true negative |
| actually a prime number (this is not known at time of input) |
prime | the input is prime | true positive |
Compare the above table to the following table describing three possible conditions (and one forbidden condition) for an algorithm that detects probable primes.
| algorithm input | algorithm output | meaning | description |
| actually a composite number (this is not known at time of input) |
composite | the input is definitely composite |
true negative |
| actually a composite number (this is not known at time of input) |
probably prime | the input is either composite or prime |
false positive |
| actually a prime number (this is not known at time of input) |
probably prime | the input is either composite or prime |
true positive |
| actually a prime number (this is not known at time of input) |
composite | impossible | false negative (we will not consider algorithms that return such outputs) |
Below is a comparison of the outputs of four possible probable prime algorithms on inputs in the range {2,...,10} ⊂ ℕ.
| input number |
perfect algorithm |
perfect probable prime algorithm |
less accurate probable prime algorithm |
very inaccurate probable prime algorithm |
| 2 | prime | probably prime |
probably prime |
probably prime |
| 3 | prime | probably prime |
probably prime |
probably prime |
| 4 | composite | composite | probably prime |
probably prime |
| 5 | prime | probably prime |
probably prime |
probably prime |
| 6 | composite | composite | composite | probably prime |
| 7 | prime | probably prime |
probably prime |
probably prime |
| 8 | composite | composite | probably prime |
probably prime |
| 9 | composite | composite | composite | probably prime |
| 10 | composite | composite | probably prime |
probably prime |
- inputs: m ∈ ℕ, k ∈ ℕ
-
-
repeat k times:
- a := a random number from {2,...,m-1}
- if a | m then return composite
- return probably prime
-
repeat k times:
- inputs: m ∈ ℕ, k ∈ ℕ
-
-
repeat k times:
- a := a random number from {2,...,m-1}
- if a | m then return composite
- if gcd(a,m) ≠ 1 then return composite
- return probably prime
-
repeat k times:
The above algorithm is somewhat problematic if we want to have a good idea of how to set k given our desired level of confidence in the output. For example, how high should k be so that the probability that we detect a composite is more than 1/2? If we require that k ≈ √(m) to be sufficiently confident in the output, we might as well use the brute force method of checking every a ∈ {2,..., ⌊ √(m) ⌋}.
To define a more predictable testing approach for our algorithm, we derive a theorem that is frequently used in applications of modular arithmetic (in fact, this fact underlies the prime number generators found in many software applications).
| ≡ |
|
| = |
| |||
| = |
|
| = |
| |||
| = |
| |||
| ≡ |
| |||
| ≡ |
| |||
- inputs: m ∈ ℕ, k ∈ ℕ
-
-
repeat k times:
- a := a random number from {2,...,m-1}
- if a | m then return composite
- if gcd(a,m) ≠ 1 then return composite
- if am-1 mod m ≠ 1 then return composite
- return probably prime
-
repeat k times:
| ≡ |
| |||
| ≡ |
|
| for the chosen a we have... |
what it means | probability of this occurring if m is a non-Carmichael composite |
| a | m | a is a non-trivial factor of m, so m is composite |
(# integers in {2,...,m-1} that are factors with m) / (m-2) |
| gcd(a,m) ≠ 1 | m and a have a non-trivial factor, so m is composite |
(# integers in {2,...,m-1} that share factors with m) / (m-2) |
| am-1 mod m ≠ 1 | a is a Fermat witness that m is composite |
at least 1/2 |
| m = 15 and a = ... | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| a | m | PP | C | PP | C | PP | PP | PP | PP | PP | PP | PP | PP | PP |
| gcd(a,m) ≠ 1 | PP | C | PP | C | C | PP | PP | C | C | PP | C | PP | PP |
| am-1 mod m = ... | 4 | 9 | 1 | 10 | 6 | 4 | 4 | 6 | 10 | 1 | 9 | 4 | 1 |
| Euclid's lemma generalization |
⇐ | multiples of coprime a in ℤ/mℤ are a permutation |
||||
| ⇑ | ||||||
| Fermat's little theorem |
random number generator |
⇒ | gcd(m,m+1) = 1 | |||
| ⇑ | ⇑ | |||||
| greatest common divisor algorithm |
⇐ | Fermat primality test |
⇐ | probable prime detector |
||
| ⇑ | ||||||
| probable prime generator |
[link] 3.8. Assignment #2: Modular Arithmetic, Random Numbers, and Primes
hw2/hw2.py. Please follow the gsubmit directions.
You may import the following library functions in your module:
from fractions import gcd
from math import log
pow() function, which can compute modular exponents efficiently (as in, ak mod n can be written in Python as pow(a,k,n)), the abs() function for computing the absolute value of an integer, and the // for integer division (you should avoid using / because it does not work for very large integers). Your file may not import any other modules or employ any external library functions associated with integers and sets unless explicitly permitted to do so in a particular problem.
Solutions to each of the programming problem parts below should be fairly concise. You will be graded on the correctness, concision, and mathematical legibility of your code. The different problems and problem parts rely on the lecture notes and on each other; carefully consider whether you can use functions from the lecture notes, or functions you define in one part within subsequent parts.
-
Solve the following equations using step-by-step equational reasoning, and list each step. You must list all solutions (zero or more) for x. You may need to use some automation to perform some of the steps (e.g., to check whether a number is prime or whether two numbers are coprime). Your solutions for this problem should appear as comments, delimited using
'''...''', inhw2.py. You may use the=ascii character to represent the ≡ relational operator on congruence classes.- 4 ⋅ x + 1 ≡ 9 (mod 17)
- x ≡ − 6 (mod 13)
- 40 ⋅ x ≡ 5 (mod 8)
- 3 ⋅ x + 1 ≡ 1 (mod 3)
- 5 ⋅ x + 7 ≡ 13 (mod 29)
- 1 + 2 ⋅ x ≡ 2 (mod 10)
- 17 ⋅ x + 11 ≡ 300 (mod 389)
- 650472472230302 ⋅ x ≡ 1 (mod 8910581811374)
- 48822616 ⋅ x ≡ 14566081015752 (mod 3333333333333333333333333)
-
Implement a function
closest(t, ks)that takes two arguments: a target integertand a list of integersks. The function should return the integerkinksthat is closest tot(i.e., the integerkinksthat minimizes the absolute value of the difference |t−k| between the two numbers). This will serve as a helper function for subsequent problems in this assignment.
>>> closest(5, [1,3,4,9,10])
4
>>> closest(8, [1,3,4,9,10])
9
-
Implement the following Python functions. These functions take advantage of the generalized Euclid's lemma to make it possible to generate a random number within a specified range. Your implementations must be extremely efficient, and must handle very large inputs, as shown in the examples below. Implementations that perform exhaustive, exponential-time searches will receive no credit.
-
Implement a function
findCoprime(m)that takes a single positive integer argumentmand returns an integerbwhereb> 1 andbis coprime withm. Your implementation does not need to return exactly the same answers as you see in the example outputs. However, the output generated by your implementation must be coprime with the input. Hint: use facts about coprime numbers (e.g., this, this, this, this, and/or this); the efficiency of the probable prime generator you must assemble in the last problem will depend on the coprimes your algorithm finds not being on the "edges" of the range.
>>> findCoprime(10)
7
>>> findCoprime(100)
63
>>> findCoprime(872637825353262)
545398640845789
>>> findCoprime(2**200)
1004336277661868922213726307713226626576376871114245522063361
>>> gcd(findCoprime(2**100000), 2**100000)
1
-
Implement a function
randByIndex(m, i)that takes two positive integer arguments:mrepresents the upper bound of random numbers to be generated, andirepresents an index specifying which random number in a the sequence should be generated. You may assumem≥ 4 and that 1 ≤i≤m− 1. The function must return theith "random" number in a permutation of the numbers {0, ...,m− 1}. Your implementation does not need to return exactly the same answers as you see in the example outputs. However, the output generated by your implementation must produce a permutation when used in a comprehension, as in the examples below.Hints:
>>> [randByIndex(10, i) for i in {0,1,2,3,4,5,6,7,8,9}]
[0, 7, 4, 1, 8, 5, 2, 9, 6, 3]
>>> [randByIndex(77, i) for i in range(0,76)]
[ 0, 48, 19, 67, 38, 9, 57, 28, 76, 47, 18, 66,
37, 8, 56, 27, 75, 46, 17, 65, 36, 7, 55, 26,
74, 45, 16, 64, 35, 6, 54, 25, 73, 44, 15, 63,
34, 5, 53, 24, 72, 43, 14, 62, 33, 4, 52, 23,
71, 42, 13, 61, 32, 3, 51, 22, 70, 41, 12, 60,
31, 2, 50, 21, 69, 40, 11, 59, 30, 1, 49, 20,
68, 39, 10, 58]
>>> randByIndex(2**200, 2**99+1)
1004336277661868922213726307713860451876490985814993873666049
- do not use floating point numbers and only use the integer division operator
//when dividing; - you can use the
m.bit_length()method to efficiently obtain the bit length of an integer.
- do not use floating point numbers and only use the integer division operator
-
Implement a function
-
Implement a function
probablePrime(m)that takes a single integer argumentmwherem>= 1. The function should returnTrueifmis probably prime, andFalseotherwise. Your code should employ the Fermat primality test by generating some number of random witnesses in the appropriate range and using them to test the primality ofm. You will need to determine what is a reasonable number of potential witnesses to test. Implementations that perform an exponentially large exhaustive search, even if the algorithm is mathematically correct, will not earn full credit.
>>> probablePrime(31)
True
>>> probablePrime(107)
True
>>> probablePrime(230204771)
True
>>> probablePrime(10738019798475862873464857984759825354679201872)
False
-
Implement a function
makePrime(d)that takes a single integer argumentdwhered>= 1 and returns a probably prime number that has exactlyddigits. Your implementation should be sufficiently efficient to produce an output ford=100in a reasonably short amount of time. Implementations that perform an exponentially large exhaustive search, even if the algorithm is mathematically correct, will not earn full credit.
>>> makePrime(2)
47
>>> makePrime(100)
3908330587430939367983163094172482420761782436265274101479718696329311615357177668931627057438461519
[link] 3.9. Multiplicative inverses
To better understand multiplicative inverses, we first review the definition of an additive inverse.
| ≡ |
| |||
| ≡ |
|
The additive inverse is 5 − 2 = 3, since 2 + 3 mod 5 = 0.
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
[link] 3.10. Chinese remainder theorem (CRT) and applications
In previous sections we presented facts that allowed us to solve certain individual equations with solution spaces corresponding to sets of congruence classes such as ℤ/mℤ. It is also possible to solve systems of equations over sets of congruence classes.
| = |
| |||
| ⋮ | |||||
| = |
|
| ≡ |
| |||
| ⋮ | |||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| = |
|
| = |
|
| ≡ |
|
| efficient modular arithmetic |
||||
| ⇓ | ||||
| Chinese remainder theorem |
⇐ | CRT solver | ⇐ | range ambiguity resolution |
| ⇑ | ||||
| Shamir secret sharing protocol |
| = |
|
| = |
|
| := |
| |||
| := |
| |||
| := |
| |||
| := |
| |||
| := |
| |||
| ⋮ |
Given our additional information about the range of the final output, we do not need to store 1000000000 bit numbers in order to perform the computation and get a correct result. It is sufficient to instead perform all the operations in ℤ/1024ℤ:
| := |
| |||
| := |
| |||
| := |
| |||
| := |
| |||
| := |
| |||
| ⋮ |
Suppose we have ten processors that can perform arithmetic computations in ℤ/28ℤ or any smaller space (such as ℤ/27ℤ). We can approach this problem by choosing a collection of primes p1,...,p10 such that 27 < pi < 28, which implies that:
| > |
| |||
| ≥ |
| ||||
| = |
| |||
| ⋮ | |||||
| = |
|
However, what if we cannot wait 12 seconds or more? For example, the obstacle may be moving quickly and we want to constantly update our best guess of the distance to that object. We would need to send signals more frequently (for example, every 5 seconds). But then if an object is 12 seconds away, we would have no way to tell when running in a steady state which of the signals we just received.
However, we can obtain some information in this scenario. Suppose we send a signal every 5 seconds, only when the clock's timer is at a multiple of 5. Equivalently, imagine the clock counts up modulo 5 (i.e., 0,1,2,3,4,0,1,2,3,4,0,...) and we only send signals when the clock is at 0. What information can we learn about the object's distance in this scenario? If the distance to the object and back is d, then we would learn d mod 5, because we would get the signal back when the clock is at 0, 1, 2, 3, or 4.
We can use multiple instances of the above device (each device using its own distinct frequency for sending signals) to build a device that can check for obstacles more frequently while not giving up too much accuracy. Pick a collection of primes p1,..., pn such that their product is greater than the distance to any possible obstacle (e.g., if this is a ship or plane, we could derive this by considering the line of sight and the Earth's curvature). Take n instances of the above devices, each with their own clock that counts in cycles through ℤ/piℤ and sends out a signal when the clock is at 0. Running in a steady state, if at any point in time the known offsets are a1,...,an, we would know the following about the distance d to an obstacle:
| ≡ |
| |||
| ⋮ | |||||
| ≡ |
|
- the product of any collection of at least k integers in M is greater than s;
- the product of any collection of k-1 integers in M is less than s.
| = |
|
[link] 3.11. Solving systems of equations with CRT solutions using multiplicative inverses
The Chinese remainder theorem guarantees that a unique solution exists to particular systems of equations involving congruence classes. But can these solutions be computed automatically and efficiently? In fact, they can. However, computing such solutions requires the ability to compute multiplicative inverses in ℤ/mℤ.| greatest common divisor algorithm |
Fermat's little theorem |
Euler's theorem |
||||
| ⇑ | ⇑ | ⇑ | ||||
| Bézout's identity |
⇐ | extended Euclidean algorithm |
⇐ | algorithm for finding multiplicative inverses |
⇒ | Euler's totient function φ |
| ⇑ | ||||||
| Chinese remainder theorem |
⇐ | CRT solver for two equations |
⇑ | |||
| induction | ⇐ | CRT solver for n equations |
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ||||||
| ≡ |
|
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| = |
| |||
| ≡ |
|
| ≡ |
|
| ||||||
| ≡ |
|
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| = |
|
| = |
|
| = |
|
| = |
| |||
| = |
| |||
| = |
|
We can repeat the above as many times as we want. Suppose we instead want Bézout's identity for 3 and 13. We can do the following:
| = |
| |||
| = |
| |||
| = |
|
| = |
|
| = |
| |||
| = |
|
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
|
| < |
|
| < |
| < |
| |||||
| < |
| < |
|
- extended Euclidean algorithm: x ∈ ℤ, y ∈ ℤ
-
- if y = 0
- (s,t) := (1, 0)
- return (s,t)
- otherwise
- (s,t) := extended Euclidean algorithm(y, x mod y)
- return (t, s - (⌊ x/y ⌋ ⋅ t) )
- if y = 0
| = |
|
| = |
| |||
| = |
| |||
| ≡ |
| |||
| = |
|
| = |
| |||
| = |
| ||||
| = |
|
| = |
|
| = |
| |||
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| = |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ⋮ | |||||
| ≡ |
|
- solve system of equations: C is a set of constraints x ≡ ai mod mi
-
- while |C| > 1
- remove two equations Ci and Cj from C and solve them to obtain a new equation x ≡ c (mod mi ⋅ mj)
- add the new equation to C
- return the one equation left in C
- while |C| > 1
[link] 3.12. More practice with CRT
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
For example, suppose we want to perform 1000 arithmetic operations on 11-bit integers. Using a single processor, this would require:
|
|
| > |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| = |
| |||
| = |
|
| ≥ |
| |||
| ≥ |
| |||
| ≥ |
| |||
| ≥ |
|
- the device that emits a sound every 3 seconds hears a response 2 seconds after each time it emits a sound;
- the device that emits a sound every 11 seconds hears a response 4 seconds after each time it emits a sound.
|
| ≡ |
| ||||||
|
| ≡ |
| ||||||
|
| ≡ |
|
- What is the lock combination?
- The lock only permits anyone to try two incorrect combinations before locking down completely and becoming inaccessible. Suppose Eve has a chance to steal either Bob's secret information or Alice's secret information, but she can only choose one. Whose information should she steal in order to unlock the lock?
| |
| |
| |
| |
|
- when the Earth revolves around the sun, it travels a circumference of 1 unit, at a rate of 1 ⋅ t (once per year);
- when the asteroid Ceres revolves around the sun, it travels a circumference of 5 units;
- when the planet Jupiter revolves around the sun, it travels a circumference of 11 units.
[link] 3.13. Euler's totient function, Euler's theorem, and applications
| = |
| |||
| = |
| |||
| = |
| ||||
| = |
|
| = |
| |||
| = |
| ||||
| = |
|
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
|
| = |
|
| = |
| |||
| = |
|
| = |
|
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
|
|
| = |
|
| = |
|
| ≡ |
| |||
| = |
| ||||
| = |
| |||
| = |
| ||||
| = |
|
| = |
|
| = |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| = |
| ||||
| = |
| ||||
| = |
|
| ≡ |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
|
| = |
| |||
| = |
|
It is sufficient to notice that 56 ≡ 1 (mod 7), so 52 ⋅ 54 ≡ 1, so 54 is the inverse of 52 in ℤ/7ℤ.
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| = |
|
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
[link] 3.14. Assignment #3: Multiplicative Inverses, CRT, and Efficient Computation
hw3/hw3.py. Please follow the gsubmit directions.
You may import the following library functions in your module (you may not need all these functions for this assignment depending on how you approach the problems, but they may be used):
from math import floor
from fractions import gcd
- the
pow()function can compute modular exponents efficiently (as in, ak mod n can be written in Python aspow(a,k,n)); - the
sum()function returns the sum of a list of integers (e.g.,sum(1,2,3,4)returns10).
Solutions to each of the programming problem parts below should be fairly concise. You will be graded on the correctness, concision, and mathematical legibility of your code. The different problems and problem parts rely on the lecture notes and on each other; carefully consider whether you can use functions from the lecture notes, or functions you define in one part within subsequent parts.
-
Solve the following equations using step-by-step equational reasoning, and list each step. For this problem, you must use Fermat's little theorem and/or Euler's theorem to compute inverses of congruence classes. Your solutions for this problem should appear as comments, delimited using
'''...''', inhw3.py. You may use the=ascii character to represent the ≡ relational operator on congruence classes.-
Solve the following equation for x ∈ ℤ/5ℤ:
8 ⋅ x ≡ 2 (mod 5) -
Solve the following system of equations for x ∈ ℤ/35ℤ:
x ≡ 1 (mod 7) x ≡ 3 (mod 5) -
Let p and q be unequal prime numbers. If p-1 ≡ 5 (mod q) and q-1 ≡ 3 (mod p), find the solution x ∈ ℤ/(p ⋅ q)ℤ to the following system of equations (your solution should be in terms of p and q):
x ≡ 4 (mod p) x ≡ 2 (mod q) -
Solve the following system of equations for a unique congruence class x, and specify the range of congruence classes in which this system of equations has a unique solution:
2 ⋅ x ≡ 3 (mod 5) x ≡ 6 (mod 14)
-
Solve the following equation for x ∈ ℤ/5ℤ:
-
Implement the following Python functions for computing multiplicative inverses of congruence classes.
-
Implement a function
invPrime(a, p)that takes two integersaandp> 1 wherepis prime. The function should return the multiplicative inverse ofa∈ ℤ/pℤ (ifa≡ 0, it should returnNone). Your solution must use Fermat's little theorem.
>>> [invPrime(i, 7) for i in range(0,7)]
[None, 1, 4, 5, 2, 3, 6]
>>> [invPrime(i, 13) for i in range(1,13)]
[1, 7, 9, 10, 8, 11, 2, 5, 3, 4, 6, 12]
-
Include the following definition in your code. This non-recursive implementation of the extended Euclidean algorithm avoids a stack overflow error on large inputs.
Given two inputs
def egcd(a, b):
(x, s, y, t) = (0, 1, 1, 0)
while b != 0:
k = a // b
(a, b) = (b, a % b)
(x, s, y, t) = (s - k*x, x, t - k*y, y)
return (s, t)
aandb,egcd(a, b)returns a solution(s, t)to the following instance of Bézout's identity:
Usinga⋅s+b⋅t= gcd(a, b)egcd(), implement a functioninv(a, m)that takes two integersaandm> 1. Ifaandmare coprime, it should return the multiplicative inverse ofa∈ ℤ/mℤ. Ifaandmare not coprime, it should returnNone.
>>> [inv(i, 13) for i in range(1,13)]
[1, 7, 9, 10, 8, 11, 2, 5, 3, 4, 6, 12]
>>> [inv(i, 8) for i in range(1,8)]
[1, None, 3, None, 5, None, 7]
-
Implement a function
-
Implement the following Python functions for solving certain systems of equations involving congruence classes.
-
Implement a function
solveOne(c, a, m)that takes three integersc,a, andm≥ 1. Ifcandmare coprime, the function should return the solution x ∈ {0, ...,m-1} to the following equation:
Ifc⋅ x≡ a(modm)candmare not coprime, the function should returnNone.
>>> solveOne(3, 4, 7)
6
>>> solveOne(1, 5, 11)
5
>>> solveOne(2, 3, 8)
None
-
Implement a function
solveTwo(e1, e2)that takes two tuplese1ande2as inputs, each of the form(c, a, m)(i.e., containing three integer elements). Each tuple(c, a, m)corresponds to an equation of the form:
Thus, the two tuples, if we call themc⋅ x≡ a(modm)(c, a, m)and(d, b, n), correspond to a system of equations of the form:
The functionc⋅ x≡ a(modm)d⋅ x≡ b(modn)solveTwo()should return the unique solution x to the above system of equations. If either equation cannot be solved usingsolveOne(), ornandmare not coprime, the function should returnNone.
>>> solveTwo((3, 4, 7), (1, 5, 11))
27
-
Implement a function
solveAll(es)that takes a list of one or more equations, each of the form(c, a, m). The list corresponds to the system of equations (assume all the mi are mutually coprime):
The functionc1 ⋅ x ≡ a1 (mod m1) ⋮ ck ⋅ x ≡ ak (mod mk) solveAll()should return the unique solution x to the above system of equations. If any individual equation cannot be solved usingsolveOne(), or if the moduli are not all mutually coprime, the function should returnNone.
>>> solveAll([(3,4,7), (1,5,11)])
27
>>> solveAll([(5,3,7), (3,5,11), (11,4,13)])
856
>>> solveAll([(1,2,3), (7,8,31), (3,5,7), (11,4,13)])
7109
>>> solveAll([(3,2,4), (7,8,9), (2,8,25), (4,4,7)])
554
-
Implement a function
-
Suppose we represent the sum of a collection of exponentiation operations as a list of tuples, where each tuple contains two integers: the base and the exponent. For example, the list
[(2,4),(3,5),(-6,3)]represents the sum of powers 24 + 35 + (−6)3.-
Implement a function
sumOfPowers(nes, ps)that takes a list of one or more tuplesnes(i.e.,nesis of the form[(a1,n1),...,(ak,nk)]) as its first argument, and a list of one or more primesps(i.e., of the form[p1,...,pm]) as its second argument. The function should return the correct result of the sum of powers as long as the following is true (e.g., on a computer with unlimited memory and time):
You may assume the second list contains distinct prime numbers. You may not assume that the numbers in the first input list have any particular patterns or relationships; they can be in any order, they can be of any size, and they may or may not share factors. Your implementation must work efficiently on very large inputs (e.g., with computations like 229999999999999999999999999999999996, as presented in the examples below).0 ≤ a1n1+ ... +aknk< p1⋅ ... ⋅pm
>>> sumOfPowers([(2,3), (5,6)], [3,5,7,11,13,17,19,23,29]) == 2**3 + 5**6
True
>>> primes =[\
15481619,15481633,15481657,15481663,15481727,15481733,15481769,15481787
,15481793,15481801,15481819,15481859,15481871,15481897,15481901,15481933
,15481981,15481993,15481997,15482011,15482023,15482029,15482119,15482123
,15482149,15482153,15482161,15482167,15482177,15482219,15482231,15482263
,15482309,15482323,15482329,15482333,15482347,15482371,15482377,15482387
,15482419,15482431,15482437,15482447,15482449,15482459,15482477,15482479
,15482531,15482567,15482569,15482573,15482581,15482627,15482633,15482639
,15482669,15482681,15482683,15482711,15482729,15482743,15482771,15482773
,15482783,15482807,15482809,15482827,15482851,15482861,15482893,15482911
,15482917,15482923,15482941,15482947,15482977,15482993,15483023,15483029
,15483067,15483077,15483079,15483089,15483101,15483103,15483121,15483151
,15483161,15483211,15483253,15483317,15483331,15483337,15483343,15483359
,15483383,15483409,15483449,15483491,15483493,15483511,15483521,15483553
,15483557,15483571,15483581,15483619,15483631,15483641,15483653,15483659
,15483683,15483697,15483701,15483703,15483707,15483731,15483737,15483749
,15483799,15483817,15483829,15483833,15483857,15483869,15483907,15483971
,15483977,15483983,15483989,15483997,15484033,15484039,15484061,15484087
,15484099,15484123,15484141,15484153,15484187,15484199,15484201,15484211
,15484219,15484223,15484243,15484247,15484279,15484333,15484363,15484387
,15484393,15484409,15484421,15484453,15484457,15484459,15484471,15484489
,15484517,15484519,15484549,15484559,15484591,15484627,15484631,15484643
,15484661,15484697,15484709,15484723,15484769,15484771,15484783,15484817
,15484823,15484873,15484877,15484879,15484901,15484919,15484939,15484951
,15484961,15484999,15485039,15485053,15485059,15485077,15485083,15485143
,15485161,15485179,15485191,15485221,15485243,15485251,15485257,15485273
,15485287,15485291,15485293,15485299,15485311,15485321,15485339,15485341
,15485357,15485363,15485383,15485389,15485401,15485411,15485429,15485441
,15485447,15485471,15485473,15485497,15485537,15485539,15485543,15485549
,15485557,15485567,15485581,15485609,15485611,15485621,15485651,15485653
,15485669,15485677,15485689,15485711,15485737,15485747,15485761,15485773
,15485783,15485801,15485807,15485837,15485843,15485849,15485857,15485863]
>>> sumOfPowers(\
[(2,29999999999999999999999999999999996)\
,(-8,9999999999999999999999999999999999)\
,(2,29999999999999999999999999999999996)\
,(7,7),(-13,3)], primes)
821346
-
Extra credit: Modify your implementation of
sumOfPowers()so that it can handle inputs even if the exponents themselves are extremely large. You must use Euler's theorem to accomplish this; you may not assume that any particular patterns will exist in the bases or exponents.
>>> sumOfPowers([(2,10**1000000 + 1), (-2,10**1000000 + 1), (3,3)], primes)
27
-
Implement a function
[link] Review #1. Properties, Algorithms, and Applications of Modular Arithmetic
This section contains a comprehensive collection of review problems going over the course material covered until this point. Many of these problems are an accurate representation of the kinds of problems you may see on an exam.-
Bob begins his algorithm by generating two coprime numbers a and m such that gcd(a,m) = 1. However, he mixes them up and defines the following computation:
Is Bob going to get a permutation? Why or why not?[ (i ⋅ m) mod a | i ∈ {1,...,a-1} ] Yes, Bob will still get a permutation because gcd(a,m) = 1, which means m mod a is also coprime with m (we can see this because this is exactly what the extended Euclidean algorithm computes before making a recursive call, or by observing that if m mod a shares a factor with a, so must m). -
Bob notices part of his mistake and tries to fix his algorithm; he ends up with the following:
How many distinct elements does the list he gets in his output contain?[ (i ⋅ m) mod m | i ∈ {1,...,m-1} ] It contains exactly one element: 0 (mod m), since all multiples of the congruence class m are equivalent to 0 (mod m). -
Bob notices his algorithm isn't returning a permutation, but he mixes up a few theorems and attempts the following fix:
Bob tests his algorithm on some m values that are prime numbers. How many elements does the set he gets in his output contain?[ (i ⋅ am-1) mod m | i ∈ {1,...,m-1} ] It contains all the elements {1,...,m-1}, generated in ascending order, since by Fermat's little theorem, am-1 ≡ 1 (mod m) if m is prime. -
Bob doesn't like the fact that his permutation doesn't look very random, so he moves the i term to the exponent:
Bob tests his algorithm on some m values that are prime numbers. How many elements does the set he gets in his output contain?[ (ai ⋅ (m-1)) mod m | i ∈ {1,...,m-1} ] It contains exactly one element: 1 (mod m), since by the consequences of Fermat's little theorem and Euler's theorem, if m is prime we have:ak ≡ ak mod φ(m) (mod m) ≡ ak mod (m-1) (mod m)
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| = |
|
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
|
|
| ≡ |
| |||
| ≡ |
|
| = |
| = |
|
|
|
| = |
|
Alternatively, we know that |ℤ/pℤ| = p and |(ℤ/pℤ)*| = φ(p) = p − 1, and p − (p − 1) = 1.
|
| = |
| |||
| = |
| ||||
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
|
- the Earth rovolves around the sun once per year;
- the asteroid Ceres rovolves around the sun every 5 years;
- the planet Jupiter revolves around the sun every 11 years.
-
Which two of these objects will align again on June 21st, and in which year?
The next time Earth and Ceres align will be in five years, in 2005, as x = 5 is the smallest non-zero solution in ℕ to the following system (the first equation represents alignment with Earth; the second equation represents alignment with Ceres):
x ≡ 0 mod 1 x ≡ 0 mod 5 -
How many years will pass before all three align again?
The smallest non-zero solution in ℕ to the following system is x = 55, so they will all align again in 2055:
x ≡ 0 mod 1 x ≡ 0 mod 5 x ≡ 0 mod 11 -
Suppose that it is June 21st of some year between 2000 and 2055. At this time, there is no alignment. However, Jupiter aligned with earth on June 21st four years ago, and Ceres aligned with Earth on June 21st one year ago. What year is it?
The following system of equations captures the situation. Since the solution must be in ℤ/55ℤ, we can find a unique solution using the Chinese remainder theorem. By inspection of the elements of 4 + 11ℤ = {4, 15, 26, ...}, the solution is x = 26.
Alternatively, we can use the formula; since x ≡ 0 (mod 1) is true for all x, there are actually only two equations:x ≡ 0 mod 1 x ≡ 1 mod 5 x ≡ 4 mod 11
Since 11 ≡ 1 (mod 5), 11-1 ≡ 1 (mod 5); we also have:x ≡ 1 mod 5 x ≡ 4 mod 11
Then the solution is:5-1 ≡ 59 (mod 11) ≡ 254 ⋅ 5 ≡ 34 ⋅ 5 ≡ 5 ⋅ 3 ⋅ 5 ≡ 4 ⋅ 5 ≡ 9 x ≡ 1 ⋅ (11 ⋅ 1) + 4 ⋅ (5 ⋅ 9) (mod (5 ⋅ 11)) ≡ 11 + 180 ≡ 191 ≡ 26
- device A: +/− 2 units
- device B: −/+ 7 units
- problems that can be solved
- generate a permutation of a set {1,...,m-1}
- generate a "random" number using permutations
- find the greatest common divisor of two relatively small integers
- check if a number is prime
- using an exhaustive search
- using the Fermat primality test
- generate a random number in a certain range
- generate a random prime in a certain range
- use random primes to...
- to share information requiring cooperation using Shamir secret sharing
- to store information on unreliable storage devices (using Shamir secret sharing)
- to perform many arithmetic operations x1 ⊕ ... ⊕ xn for some operator ⊕ in sequence more efficiently (using CRT)
- if the range of the final output is known
- if working in parallel along multiple distinct pi in ℤ/piℤ, and then performing CRT once is less expensive than working in ℤ/nℤ the whole time
- solving equations and performing computations
- solve a system of linear equations where each equation is modulo some ni and the coefficient is coprime with the moduli
- derive a system of equations from a word problem
- rotating objects
- objects that generate/consume different amounts of power
- Shamir secret sharing and applications
- solve a system with additive and multiplicative inverses
- solve generalized cases (gcd(n,m) > 1 and/or c > 1 in c ⋅ x ≡ a (mod n))
- solve a system of three or four equations
- derive a system of equations from a word problem
- compute exponents modulo n efficiently
- using Euler's theorem and φ (when possible)
- using the efficient repeated-squaring method
- compute multiplicative inverses ℤ/nℤ
- using φ(n)
- using a given output from the extended Euclidean algorithms or (equivalently) an instance of Bézout's identity
- solve a system of linear equations where each equation is modulo some ni and the coefficient is coprime with the moduli
- recognize when you cannot solve problems efficiently
- computing φ(n) for prime n or composite n with no powers of primes in its factorization
- factoring n for an arbitrary n
[link] 4. Computational Complexity of Modular Arithmetic Algorithms
[link] 4.1. Definition of computational problems and their complexity
Below, we review a small set of definitions and facts from complexity theory. We will only use these facts as they relate to problems in modular arithmetic and abstract algebra. A course on computational complexity theory would go into more detail.- "Given x, find y such that f(x, y) is true."
[link] 4.2. Complexity of algorithms for solving tractable problems
In this subsection we consider the running time of efficient algorithms for performing common arithmetic operations (addition, subtraction, multiplication, exponentiation, and division). We consider the complexity of these arithmetic operations on each of the following domains:- unbounded positive integers;
- integers modulo 2n;
- integers modulo k for some k ∈ ℕ.
|
|
| = |
| |||
| = |
| |||
| = |
|
- the first (left-hand side) input is x, an n-bit integer;
- the second (right-hand side) input is y, an m-bit integer.
- addition of unbounded positive integers: n-bit integer x, m-bit integer y
-
- r (a bit vector to store the result)
- c := 0 (the carry bit)
- for i from 0 to max(n,m)-1
- r[i] := (x[i] xor y[i]) xor c
- c := (x[i] and y[i]) or (x[i] and c) or (y[i] and c)
- r[max(n,m)+1] := c
- return r
A more efficient approach is to use the representation of x as a sum of powers of 2, and to apply the distributive property. Suppose x is represented as the binary bit string an-1...a0. Then we have:
| = |
| |||
| = |
|
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
- multiplication of unbounded positive integers: n-bit integer x, m-bit integer y
-
- r (a bit vector to store the result)
- for i from 0 to n-1
- if x[i] is 1
- r := r + y (using unbounded integer addition)
- shift the bits of y left by one bit (i.e., multiply y by 2)
- if x[i] is 1
- return r
- exponentiation of unbounded positive integers: n-bit integer x, m-bit integer y
-
- r (a bit vector to store the result)
- for i from 0 to m-1
- if y[i] is 1
- r := r ⋅ x (using unbounded integer multiplication)
- x := x ⋅ x (using unbounded integer multiplication)
- if y[i] is 1
- return r
- integer division of unbounded positive integers: n-bit integer x, m-bit integer y
-
- if y > x
- return 0
- for i from 0 to n-1
- shift y left by one bit
- r (a bit vector to store ⌊ x / y ⌋ ⋅ y)
- q (a bit vector to store the integer quotient)
- p := 2n-1 (to keep track of the current power of 2)
- for i from 0 to n-1
- if r+y < x
- r := r+y (using unbounded integer addition)
- q := q+p (using unbounded integer addition)
- shift y right by one bit
- shift p right by one bit
- if r+y < x
- return q
- if y > x
| = |
|
- if b ≤ (1/2) ⋅ a, then ⌊ a / b ⌋ > 1, so:
(a mod b) < b ≤ (1/2) ⋅ a - if b > (1/2) ⋅ a, then ⌊ a / b ⌋ = 1, so:
a mod b = a - ⌊ a/b ⌋ ⋅ b = a - 1 ⋅ b = a - b < a - ((1/2) ⋅ a) < (1/2) ⋅ a
If all inputs and outputs are integers that can be represented with at most n bits, the running time is then O(n3).
If all inputs and outputs are integers that can be represented with at most n bits, the running time is then O(n3).
| ≡ |
| |||
| ≡ |
|
If all inputs and outputs are integers that can be represented with at most n bits, the running time is then O(n3).
| = |
| |||
| = |
|
[link] 4.3. Complexity of (probably) intractable problems
In the previous section we saw that addition, subtraction, multiplication, exponentiation, and division (both integer division, modulus, and multiplication by multiplicative inverses) can all be computed efficiently (i.e., in polynomial time) both over integers and over congruence classes. It is also possible to efficiently compute roots and logarithms of integers (we omit proofs of this fact in this course). However, no efficient algorithms are known for computing roots and logarithms of congruence classes.| solver for problem B |
⇒ ⇒ ⇒ |
conversion from output(s) from B to output from A |
| ⇑⇑⇑ | ⇓ | |
| conversion from input for A to input(s) for B |
⇐ | solver for problem A |
| problem B | ⇐ | problem A |
| finding multiplicative inverses |
⇐ | solving two-equation systems using CRT |
To see why B cannot be in P, we can present a proof by contradiction. Suppose that there does exist a polynomial-time algorithm to solve problem B. Then the polynomial-time reduction from A to B can invoke a polynomial-time algorithm. But then the reduction and algorithm for B working together will constitute a polynomial-time algorithm to solve A. Then it must be that A is in P. But this contradicts the fact that A is not in P, so no such polynomial-time algorithm for B could exist.
| problem B premise: can be solved in polynomial time B ∈ P |
⇐ | problem A conclusion: can be solved in polynomial time A ∈ P |
| problem B conclusion: cannot be solved in polynomial time B ∉ P |
⇐ | problem A premise: cannot be solved in polynomial time A ∉ P |
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
|
| = |
| |||
| = |
|
We can plug n and φ(n) into the system of equations derived in the applicable fact:
| = |
| |||
| = |
|
| = |
| |||
| = |
| |||
| = |
| ||||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| = |
| |||
| ∈ |
| |||
| = |
|
If we can compute φ(n), then we can compute p and q. If computing φ(n) were any easier than factoring n (e.g., if we had a polynomial-time algorithm for computing φ(n)), then our claim about the hardness of factoring n would be a contradiction. In other words, factoring n can be reduced to solving φ(n).
| computing φ(n) conclusion: cannot be solved in polynomial time computing φ(n) ∉ P |
⇐ | factoring n conjecture: cannot be solved in polynomial time factoring ∉ P |
Suppose we are given the following equation:
| = |
|
- given x and y, compute z (this is the exponentiation operation);
- given x and z, compute y (this is the logarithm operation, since we have logx z = y in an equivalent notation);
- given y and z, compute x (this is the yth root operation, since we have y√(z) = x in an equivalent notation).
| ≡ |
|
| = |
|
| ||||||
| ∈ |
|
| ||||||
| = |
|
|
| = |
| = |
|
| ∈ |
| |||||||
| ∈ |
| |||||||
| = |
|
|
| = |
| = |
|
Before we formally define the problem of computing square roots in ℤ/nℤ, we must first introduce some concepts and facts. This is because the problem of computing square roots in ℤ/nℤ is different from the problem of computing square roots of integers in ℕ, and this difference is likely what makes it computationally more difficult.
| |
| |
| |
| |
| |
| |
|
| |
| |
| |
| |
|
Note that this is analogous to square roots in ℤ (since √(z) ∈ ℤ and −√(z) ∈ ℤ are both square roots of z ∈ ℤ if they exist).
We can prove this fact in the following way: suppose that y is a quadratic residue. Then there exists at least one x ∈ ℤ/nℤ such that:
| = |
|
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| |||
| = |
| |||
| = |
| ||||
| |
| |
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
|
| = |
| |||
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| |||
| = |
| ||||
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
|
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| = |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| | |
|
| | |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
| = |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| ||||
| ≡ |
|
| ≡ |
|
| = |
|
Suppose we are using a range ambiguity resolution technique to track the distance the object has travelled. If it a particular moment, we know that the distance from the object is in the congruence class 10 + 11ℤ, what can we say about the amount of time t that has elapsed since the object started moving?
Since the distance is in 10 + 11ℤ, we can say:
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
- If n is a prime p, the possibilities are:
- a is not a quadratic residue in ℤ/pℤ, so there are no solutions to the equation,
- a ≡ 0, in which case x ≡ 0 is the one and only solution to the equation,
- a is a quadratic residue in ℤ/pℤ, so there are exactly two solutions to the equation, ± x ∈ ℤ/pℤ.
- If n is prime power pk+1 and a is coprime with p, the possibilities are:
- a is not a quadratic residue in ℤ/pkℤ, so it is not a quadratic residue in ℤ/pk+1ℤ;
- a is a quadratic residue in ℤ/pkℤ, and both square roots of a in ℤ/pkℤ can be "lifted" to ℤ/pk+1ℤ using Hensel's lemma.
- If n is a product of two coprime numbers k and m, then there is a solution in ℤ/nℤ for every possible combination of y and z such that:
Each combination corresponds to a solution x ∈ ℤ/nℤ defined using CRT as:y2 ≡ a mod k z2 ≡ a mod m x ≡ y mod k x ≡ z mod m
| = |
|
Factoring can be reduced to finding congruent squares. Suppose we want to factor n. We find x and y such that:
| = |
| |||
| = |
| |||
| = |
| ||||
| | |
|
| congruent squares (square roots of congruence classes) |
||||
| ⇑ | ⇑ | |||
| computing φ(n) for n = p ⋅ q |
⇐ ⇒ |
factoring n = p ⋅ q |
||
| ⇑ | ⇑ | |||
| RSA problem (eth roots of congruence classes) |
||||
| discrete logarithm (logarithms of congruence classes) |
||||
[link] 4.4. Applications of intractability
The computational intractability of certain problems in modular arithmetic makes it possible to address some practical security issues associated with implementing communication protocols. In particular, it helps address two common problems:- parties must communicate over a public communications channel, so everything they send is visible both to their receiver and to anyone that may be eavesdropping;
- parties trying to communicate cannot physically meet to agree on shared secret information before communicating.
In order to help Bob confirm that a message is truly from Alice (or to determine which message is from Alice given multiple messages), Alice and Bob meet in person and agree on a secret identifier s. When Alice decides to send a message m to Bob, she will send (m, s). Bob can then compare s to his own copy of s and confirm the message is from Alice.
Eve's only attack strategy is to try and guess s. As long as Alice and Bob choose s from a very large range of integers, the probability that Eve can guess s correctly is small.
- choose two large primes p and q at random;
- compute n = p ⋅ q;
- send the public identifier n to Bob over a public/non-secure communication channel.
If it were possible to quickly (i.e., in polynomial time) compute the private identifier, then it would be easy to forge the identity of a sender by recording their public identifier n. However, suppose that this forging computation could be used as a subprocedure in a factoring algorithm. Then it would be possible to implement an efficient factoring algorithm. In other words, factoring n can be reduced to forging a private identifier. Thus, the problem of forging a private identifier must not be in P (i.e., the fastest algorithm that exists for forging an identity is not in P, which means there is no polynomial-time for forging an identity).
| forging private identifier for n conclusion: cannot be solved in polynomial time forging ∉ P |
⇐ | factoring n conjecture: cannot be solved in polynomial time factoring ∉ P |
| alternative efficient algorithm |
⇐ | forging private identifier for n |
⇒ | factoring n |
However, the protocol still has many other flaws. For example, Eve could preempt Alice and send her own signature n before Alice has a chance to send her signature to Bob. A more thorough examination of such protocols is considered in computer science courses focusing explicitly on the subject of cryptography.
- Public key generation (performed by one party):
- Randomly choose a public large prime number p ∈ ℕ and an element g ∈ ℤ/pℤ.
- Private key generation (performed by both parties):
- Party A randomly chooses a secret a ∈ ℤ/φ(p)ℤ.
- Party B randomly chooses a secret b ∈ ℤ/φ(p)ℤ.
- Protocol:
- Party A computes (ga mod p) and sends this public value to party B.
- Party B computes (gb mod p) and sends this public value to party A.
- Party A computes (gb mod p)a mod p.
- Party B computes (ga mod p)b mod p.
- Since multiplication over ℤ/φ(p)ℤ is commutative, both parties now share a secret ga ⋅ b mod p.
- a sender wants to send the receiver a secret message over a public channel;
- a receiver wants to allow any number of senders to send him messages over a public channel, and the receiver does not yet know who the senders will be.
- Key generation (performed by the receiver):
- Randomly choose two secret prime numbers p ∈ ℕ and q ∈ ℕ of similar size.
- Compute a public key value n = p ⋅ q.
- Compute the secret value φ(n) = (p-1) ⋅ (q-1).
- Choose a public key value e ∈ {2,...,φ(n)-1} such that gcd(e, φ(n)) = 1.
- Compute the secret private key d = e-1 mod φ(n)
- Protocol (encryption and decryption): There are two participants: the sender and the receiver.
- The sender wants to send a message m ∈ {0,...,n-1} where gcd(m,n) = 1 to the receiver.
- The receiver reveals the public key (n,e) to the sender.
- The sender computes the ciphertext (encrypted message) c = me mod n.
- The sender sends c to the receiver.
- The receiver can recover the original message by computing m = cd mod n.
| ≡ |
| |||
| = |
| ||||
| = |
| |||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
| ||||
| = |
|
- p and q
- φ(n)
- d = e-1
Suppose the eavesdropper only knows φ(n). Then the eavesdropper can compute d and decrypt any message. In fact, the eavesdropper can also recover p and q.
- Key generation (performed by the receiver):
- Randomly choose two secret prime numbers p ∈ ℕ and q ∈ ℕ of similar size.
- Compute a public key value n = p ⋅ q.
- Protocol (encryption and decryption): There are two participants: the sender and the receiver.
- The sender wants to send a message m ∈ {0,...,n-1} to the receiver.
- The receiver reveals the public key n to the sender.
- The sender computes the ciphertext (encrypted message) c = m2 mod n.
- The sender sends c to the receiver.
- The receiver can recover the original message by computing √(c) in ℤ/pℤ and ℤ/qℤ,
and then finding the four solutions to the following system by using the Chinese remainder theorem:
m ≡ √(c) mod p m ≡ √(c) mod q.
| breaking Rabin encryption |
⇐ | congruent squares (square roots of congruence classes) |
||||
| ⇑ | ⇑ | |||||
| finding RSA secret key |
⇐ | computing φ(n) for n = p ⋅ q |
⇐ ⇒ |
factoring n = p ⋅ q |
||
| ⇑ | ⇑ | |||||
| decrypting individual RSA messages |
⇐ | RSA problem (eth roots of congruence classes) |
||||
| breaking Diffie-Hellman |
⇐ | discrete logarithm (logarithms of congruence classes) |
||||
- every day, Bob chooses two new random primes p and q;
- Bob computes n = p ⋅ q, and then discards p and q;
- Bob posts n online for everyone to see;
- at any time on that day, anyone can submit a factor f of n;
- if f is a factor of n, Bob issues that person a BobCoin, invalidates n permanently so that no one else can use it, and generates a new n.
-
Why is it okay for Bob to discard p and q?
Because Bob can easily check whether a submitted f actually is a factor by computing gcd(f, n), or simply dividing n by f.
-
Suppose that Bob always posts numbers n that have 100 digits, and it takes the fastest computer one year to factor a 100-digit number through trial and error. If Alice wants to earn a BobCoin in one day, how many computers will Alice need to run in parallel to earn a BobCoin?
Since it takes a 365 days to try all possible k factors of a 100-digit number, in one day one computer can try 1/365 ⋅ k factors. Thus, Alice would need 365 computers that she could run for one day, with each computer looking through a different region of factors.
-
Suppose Bob wants to issue a complimentary BobCoin coupon to a group of 100 people. However, he wants to make sure that they can use their BobCoin coupon only if at least 20 out of those 100 people agree that the coupon should be redeemed for a BobCoin. How can Bob accomplish this?
Bob can use Shamir secret sharing to accomplish this. Bob can take one of the factors f of n when he generates n, and choose 100 distinct primes such that the product of any 20 of the primes is greater than f while the product of any 19 of these primes is less than f. Bob can then distribute f mod m for each prime modulus m to each of the 100 people. If any 20 (or greater) of these 100 people agree to redeem the coupon, then can use CRT to reconstruct f and submit it to Bob for redemption.
[link] 4.5. Assignment #4: Intractable Problems in Modular Arithmetic
hw4.py (submitted to the location hw4/hw4.py). Please follow the gsubmit directions.
You may import the following library functions in your module (you may not need all these functions for this assignment depending on how you approach the problems, but they may be used):
from math import floor
from fractions import gcd
-
Solve the following equations using step-by-step equational reasoning, and list each step. Your solutions for this problem should appear as comments, delimited using
'''...''', inhw4.py. You may use the=ascii character to represent the ≡ relational operator on congruence classes.-
Solve the following equation for all solutions x ∈ ℤ/23ℤ:
x2 ≡ 3 (mod 23) -
Solve the following equation for all solutions x ∈ ℤ/43ℤ:
x2 ≡ 25 (mod 43) -
Solve the following equation for all solutions x ∈ ℤ/41ℤ (note that you cannot use the explicit formula for square roots in this case):
3 ⋅ x2 ≡ 7 (mod 41) -
Solve the following equation for all solutions x ∈ ℤ/49ℤ:
x2 ≡ 11 (mod 49) -
Solve the following equation for all solutions x ∈ ℤ/21ℤ:
(8 ⋅ x2) + 4 ≡ 6 (mod 21) -
Using congruence classes, explain why the following equation involving integers cannot have any integer solutions x ∈ ℤ:
x5 + x + 1 = 256
-
Solve the following equation for all solutions x ∈ ℤ/23ℤ:
-
Implement the following Python functions for factoring a positive integer. These algorithms must be efficient (i.e., they must run in polynomial time).
-
Implement a function
factorsFromPhi(n, phi_n)that takes two integersnandphi_n. You may assume (i.e., you do not need to verify in your code) thatnis a product of two distinct positive prime numbers and thatphi_n= φ(n). The function should return both prime factors ofnas a tuple.
>>> factorsFromPhi(77, 60)
(7, 11)
>>> factorsFromPhi(14369648346682547857, 14369648335605206820)
(9576890767, 1500450271)
-
Implement a function
factorsFromRoots(n, x, y)that takes three integersn,x, andy. You may assume thatnis a product of two distinct positive prime numbers, and that the following is true:
The function should return both prime factors ofx2≡ y2 (modn)x≢ ± y(modn)nas a tuple.
>>> factorsFromRoots(35, 1, 6)
(5, 7)
>>> factorsFromRoots(14369648346682547857, 12244055913891446225, 1389727304093947647)
(1500450271, 9576890767)
-
Consider the following problem (call it "φ-four"): "given an integer n = p ⋅ q ⋅ r ⋅ s that is the product of four distinct primes, find φ(n)." Notice that the four distinct primes are not known in the specification of the problem. It is only known that n is the product of some four distinct primes.Given our assumptions about the intractability of various problems (i.e., that certain problems are not in P), you must show that φ-four is also not in P. To do so, you must implement a function
phiFromPhiFour(n)for the existing intractable problem of computing φ that uses a solver for φ-four (call itphi_four()) as a subroutine. Note: remember that the four primes must be distinct; your reduction must work for all possible instances of the intractable problem.
-
Implement a function
-
In this problem you will implement the three component algorithms of the RSA cryptographic protocol described in lecture.
-
Define a Python function
generate(k)that takes a single integer inputkand returns a tuple(n,e,d)corresponding to the public valuesnandeand private keydin the RSA cryptographic protocol. The outputnmust be the product of two distinct, randomly chosenk-digit primes. You may import and use the Python random number generator (from random import randomorfrom random import randint), and you may want to reuse the extended Euclidean algorithm implementation provided in the previous homework assignment. -
Define a Python function
encrypt(m, t)that takes two inputs: an integermand a tuple(n,e)representing an RSA public key. It should return a single integer: the RSA ciphertextc. -
Define a Python function
decrypt(c, t)that takes two inputs: an integercrepresenting the ciphertext and a tuple of two integers(n,d)representing an RSA private key. It should decryptcand return the original messagem.
-
Define a Python function
-
In this problem you will implement an algorithm for computing all the square roots of a congruence class in ℤ/nℤ, given a complete factorization of n into its distinct prime factor powers (assuming all the prime factors are in 3 + 4ℤ).
-
Implement a Python function
sqrtsPrime(a, p)that takes two arguments: an integeraand a prime numberp. You may assume thataandpare coprime. Ifpis not in 3 + 4ℤ orahas no square roots in ℤ/pℤ, the function should returnNone. Otherwise, it should return the two congruence classes in ℤ/pℤ that solve the following equation:x2 ≡ a(modp)
>>> sqrtsPrime(2, 7)
(3, 4)
>>> sqrtsPrime(5, 7) # 5 has no square roots
None
>>> sqrtsPrime(5, 17) # 17 mod 4 =/= 3
None
>>> sqrtsPrime(763472161, 5754853343)
(27631, 5754825712)
-
Implement a Python function
sqrtsPrimePower(a, p, k)that takes three arguments: an integera, a prime numberp, and a positive integerk. You may assume thataandpare coprime. Ifpis not in 3 + 4ℤ orahas no square roots in ℤ/pkℤ, the function should returnNone. Otherwise, it should return the congruence classes in ℤ/pkℤ that solve the following equation:x2 ≡ a(modpk)
>>> sqrtsPrimePower(2, 7, 2)
(10, 39)
>>> sqrtsPrimePower(763472161, 5754853343, 4)
(27631, 1096824245608362247285266960246506343570)
-
Implement a Python function
sqrts(a, pks)that takes two arguments: an integeraand a list of tuplespksin which each tuple is a distinct positive prime number paired with a positive integer power. You may assume thataandnare coprime. You may assume that all the primes inpksare in 3 + ℤ/4ℤ (if any are not, the function should returnNone). Letnbe the product of all the prime powers in the listpks. Then the function should return a set of all the distinct square roots ofain ℤ/nℤ that are solutions to the following equation:
Your implementation must be efficient (i.e., it may not iterate over all possible values in ℤ/x2 ≡ a(modn)nℤ to look for square roots), and it must work for any positive number of entries inpks.You may find the following helper function useful in implementing your solution.
>>> sqrts(2, [(7,4)])
{235, 2166}
>>> sqrts(1, [(7,1), (11,1)])
{1, 76, 43, 34}
>>> sqrts(1, [(7,1), (11,1), (3,1)])
{1, 76, 43, 34, 155, 188, 197, 230}
>>> sqrts(1, [(7,2), (11,1), (3,2)])
{1, 197, 881, 1079, 3772, 3970, 4654, 4850}
>>> sqrts(1, [(7,1), (11,1), (3,1), (19,1)])
{1, 265, 419, 1198, 1310, 1462, 1616, 1882, 2507, 2773, 2927, 3079, 3191, 3970, 4124, 4388}
>>> sqrts(76349714515459441, [(1500450271,3), (5754853343,2)])
{276314521,
111875075121925861006908948065990250824231090118,
50900491283175338098734392241768315796265192809,
60974583838750522908174555824221935028242211830}
This function takes a list of lists as its input and returns a list of all possible combinations of one element from each list.
def combinations(ls):
if len(ls) == 0:
return [[]]
else:
return [ [x]+l for x in ls[0] for l in combinations(ls[1:]) ]
>>> combinations([[1,2], ['a','b'], ['X','Y']])
[[1, 'a', 'X'], [1, 'a', 'Y'], [1, 'b', 'X'], [1, 'b', 'Y'], [2, 'a', 'X'], [2, 'a', 'Y'], [2, 'b', 'X'], [2, 'b', 'Y']]
-
Implement a Python function
-
Suppose you are supplied with an efficient implementation of an algorithm for breaking the Rabin cryptographic protocol. Below, we provide a mockup of an efficient implementation of such an algorithm that only work on a few sample inputs (since we do not believe efficient algorithms for breaking this protocol exists, we must cheat in this way in order to test our code). You may assume that the below algorithm works on all inputs, not just those provided in the fake implementation.
Implement an efficient function
# Efficiently computes m from (pow(m,2,n), n).
def decryptMsgRabin(c, n):
input_output = {\
(14, 55): 17,\
(12187081, 8634871258069605953): 7075698730573288811,\
(122180308849, 16461679220973794359): 349543,\
(240069004580393641, 19923108241787117701): 489968371\
}
return input_output[(c, n)]
roots(a, n)that takes two integersaandnand returns all four square roots ofain ℤ/nℤ as a tuple. You may assume thatnis the product of two distinct positive prime numbers. Your algorithm in this problem must work on all possible inputs under the assumption thatdecryptMsgRabin()also works on all inputs (not just the fake inputs handled by the definitions above) and that an encrypted message c is never represented by the same congruence class as the original, unencrypted message m or − m (i.e., the implementation follows the guideline regarding good ranges for messages at the end of the definition of the Rabin protocol).
>>> roots(12187081, 8634871258069605953)
(3491, 8634871258069602462, 1559172527496317142, 7075698730573288811)
[link] 5. Algebraic Structures
In the previous sections, we studied a specific algebraic structure, ℤ/nℤ, as well as its operations (e.g., addition, multiplication), and its properties (commutativity, associativity, and so on). There exist many other algebraic structures that share some of the properties of ℤ/nℤ. In fact, we can create a hierarchy, or even a web, of algebraic structures by picking which properties of ℤ/nℤ we keep and which we throw away.Showing that some new algebraic structure is similar or equivalent to another, more familiar structure allows us to make inferences about that new structure based on everything we already know about the familiar structure. In computer science, the ability to compare algebraic structures using their properties is especially relevant because every time a programmer defines a new data structure and operations on that data structure, they are defining an algebraic structure. Which properties that algebraic structure possesses determines what operations can be performed on it, in what order they can be performed, how efficiently they can be performed, and how they can be broken down and reassembled.
[link] 5.1. Permutations
Recall that a permutation on a set X is a bijective relation between X and X (i.e., a subset of the set product X × X). Since a permutation is a bijective map (i.e., a function), we can reason about composition of permutations (it is just the composition of functions). Thus, we can study sets of permutations as algebraic structures under the composition operation o.Notice that for any set X of finite size n, we can relabel the elements of X to be {0,...,n-1} (that is, we can define a bijection between X and {0,...,n-1}). Thus, we can study permutations on {0,...,n-1} without loss of generality. We will adopt the following notation for permutations:
|
|
Suppose we want to construct a permutation [a1,...,an] using the elements in {0,...,n-1}, where we are only allowed to take each element in the set once and assign it to an unassigned entry ai. Then for the first slot, we have n possibilities; for the second, we have n-1 possibilities. For the third, we have n-2 possibilities, and so on until we have only one possibility left. Thus, the number of possible permutations we can make is:
| = |
|
|
|
[link] 5.2. Isomorphisms: Equivalence of Algebraic Structures
An algebraic structure is a set together with a binary operator over that set. All algebraic structures are closed under their binary operation.
| = |
|
| = |
| |||
| = |
| |||
| = |
| |||
- there exists a bijection (i.e., a bijective relation) between A and B, which we denote using = ;
- for all a, a' ∈ A and b,b' ∈ B, if a = b and a' = b' then a ⊕ a' = b ⊗ b'.
- there exists a bijective map m between A and B;
- for all a, a' ∈ A, m(a ⊕ a') = m(a) ⊗ m(a').
| S2 | ℤ/2ℤ |
| [0,1] | 0 |
| [1,0] | 1 |
| S2 | ℤ/2ℤ |
| [0,1] o [0,1] = [0,1] | 0 + 0 = 0 |
| [0,1] o [1,0] = [1,0] | 0 + 1 = 1 |
| [1,0] o [0,1] = [1,0] | 1 + 0 = 1 |
| [1,0] o [1,0] = [0,1] | 1 + 1 = 0 |
| + o |
0 [0,1] |
1 [1,0] |
| 0 [0,1] |
0 [0,1] |
1 [1,0] |
| 1 [1,0] |
1 [1,0] |
0 [0,1] |
| C3 | ℤ/3ℤ |
| [0,1,2] o [0,1,2] = [0,1,2] | 0 + 0 = 0 |
| [0,1,2] o [1,2,0] = [1,2,0] | 0 + 1 = 1 |
| [0,1,2] o [2,0,1] = [2,0,1] | 0 + 2 = 2 |
| [1,2,0] o [0,1,2] = [1,2,0] | 1 + 0 = 1 |
| [1,2,0] o [1,2,0] = [2,0,1] | 1 + 1 = 2 |
| [1,2,0] o [2,0,1] = [0,1,2] | 1 + 2 = 0 |
| [2,0,1] o [0,1,2] = [2,0,1] | 2 + 0 = 2 |
| [2,0,1] o [1,2,0] = [0,1,2] | 2 + 1 = 0 |
| [2,0,1] o [2,0,1] = [1,2,0] | 2 + 2 = 1 |
| = |
| |||
| = |
|
Note that |ℤ/φ(p)ℤ| = φ(p) = |(ℤ/pℤ)*|.
| (ℤ/2ℤ, +) | ((ℤ/3ℤ)*, ⋅) |
| 0 + 0 = 0 | 1 ⋅ 1 = 1 |
| 0 + 1 = 1 | 1 ⋅ 2 = 2 |
| 1 + 0 = 1 | 2 ⋅ 1 = 2 |
| 1 + 1 = 0 | 2 ⋅ 2 = 1 |
| (ℤ/2ℤ, +) | ((ℤ/6ℤ)*, ⋅) |
| 0 + 0 = 0 | 1 ⋅ 1 = 1 |
| 0 + 1 = 1 | 1 ⋅ 5 = 5 |
| 1 + 0 = 1 | 5 ⋅ 1 = 5 |
| 1 + 1 = 0 | 5 ⋅ 5 = 1 |
| ≡ |
|
| ≡ |
|
| ℤ/3ℤ | ℤ/3ℤ |
| 0 | 0 |
| 1 | 2 |
| 2 | 1 |
| ℤ/3ℤ | ℤ/3ℤ |
| 0 + 0 = 0 | 0 + 0 = 0 |
| 0 + 1 = 1 | 0 + 2 = 2 |
| 0 + 2 = 2 | 0 + 1 = 1 |
| 1 + 0 = 1 | 2 + 0 = 2 |
| 1 + 1 = 2 | 2 + 2 = 1 |
| 1 + 2 = 0 | 2 + 1 = 0 |
| 2 + 0 = 2 | 1 + 0 = 1 |
| 2 + 1 = 0 | 1 + 2 = 0 |
| 2 + 2 = 1 | 1 + 1 = 2 |
| = |
| |||
| = |
| |||
| = |
|
| = |
|
What Alice can do before she stores anything in Eve's database is to pick some secret a ∈ ℤ/nℤ that is coprime with n. Then, every time Alice needs to store some b in Eve's database, Alice will instead send Eve the obfuscated value (a ⋅ b) mod n. Since a is coprime with n, there exists a-1 ∈ ℤ/nℤ. Thus, if Alice retrieves some obfuscated data entry c from Eve's database, she can always recover the original value by computing (a-1 ⋅ c) mod n, because:
| ≡ |
|
| = |
|
| = |
|
We assume that Alice knows or can easily compute φ(n), while Eve does not know and cannot compute it (perhaps Alice generated n using a method similar to the one in RSA encryption protocol).
What Alice can do before she stores anything in Eve's database is to pick some secret e ∈ ℤ/φ(n)ℤ that is coprime with φ(n). Since Alice knows e and φ(n), she can compute e-1 using the extended Euclidean algorithm.
Then, every time Alice needs to store some b in Eve's database, Alice will instead send Eve the encrypted value be mod n. If Alice retrieves some encrypted data entry c from Eve's database, she can always recover the original value by computing (ce-1}) mod n, because by Euler's theorem:
| ≡ |
| ≡ |
|
| = |
|
| = |
|
| ≡ |
| ≡ |
|
| ≡ |
|
| ≡ |
|
[link] 5.3. Generators of Algebraic Structures
Because an algebraic structure (A,⊕) often consists of a set of objects that can be "built up" using the binary operator ⊕ from a smaller, possibly finite, collection of generators G ⊂ A, it is often easier to reason about an algebraic structure by first reasoning about its generators, and then applying structural induction.
| = |
|
| = |
|
| = |
|
| = |
|
| = |
| |||
| = |
| |||
| ⊂ |
| |||
| ⊂ |
| |||
| = |
| |||
[link] 5.4. Assignment #5: Algebraic Structures and Isomorphisms
hw5.py (submitted to the location hw5/hw5.py). Please follow the gsubmit directions.
You may import the following library functions in your module (you may not need all these functions for this assignment depending on how you approach the problems, but they may be used):
from math import floor
from fractions import gcd
from random import randint
from urllib.request import urlopen
-
Solve the following equations using step-by-step equational reasoning, and list each step. Your solutions for this problem should appear as comments, delimited using
'''...''', inhw5.py.-
Compute the following composition of permutations (the result should be a permutation):
[3,5,4,0,1,2] o [4,5,3,1,2,0] = ? -
Compute the following composition of permutations (the result should be a permutation):
[71,72,...,99,0,1,2,3,4,...,70] o [11,12,...,99,0,1,2,3,4,...,10] = ? -
Let p ∈ S7 be a swap permutation on 7 elements. Compute the following (your result should be an explicit permutation):
p o p o p o p = ? -
Let p, q ∈ C11 be two distinct cyclic permutation on 11 elements. Compute the following (your result should be an explicit permutation):
p o q o p-1 o q-1 = ? - Define the isomorphism between the two algebraic structures (C2, o) and ((ℤ/4ℤ)*, ⋅). You must write down a bijection that specifies how each element in C2 corresponds to an element of (ℤ/4ℤ)*, and you must write down four pairs of corresponding equation that show that the behavior of o on elements of C2 is the same as the behavior of ⋅ on corresponding elements of (ℤ/4ℤ)*.
- Define the isomorphism between the two algebraic structures (closure({2 + 15ℤ}, ⋅), ⋅) and (ℤ/4ℤ, +) (where ⋅ in the first case refers to multiplication modulo 15). You must write down a bijection that specifies how each element in closure({2 + 15ℤ}, ⋅) corresponds to an element of ℤ/4ℤ, but you do not need to write out all the equations.
- Explain why there can be no isomorphism between the two algebraic structures (S6, o) and (ℤ/6ℤ, +).
-
Compute the following composition of permutations (the result should be a permutation):
-
Implement the following Python functions for working with permutations. Any code that does not conform exactly to the specified requirements will receive no credit.
-
Implement a function
permute(p, l)that takes two arguments: a permutationp(represented as a Python list of integers) and a listlof the same length as the permutation. It should return the list after it has been permuted according to the permutation.
>>> permute([2,1,0], ['a','b','c'])
['c','b','a']
-
Implement a function
C(k, m)that takes two integerskandmwherek<mand returns the cyclic permutation in Cm that shifts all elements up by k.
>>> C(1, 4)
[1, 2, 3, 0]
-
Implement a function
M(a, m)that takes two coprime integersaandmwhere0<a<mand returns the multiplication-induced permutation in Mm that corresponds to multiplication by a modulo m:
>>> M(2, 5)
[0, 2, 4, 1, 3]
-
Implement a function
sort(l)that takes a list of integers of some length n and returns:- a cyclic permutation p ∈ Cn that will sort the list into ascending order, if it exists;
- a multiplication-induced permutation p ∈ Mn that will sort the list into ascending order, if it exists;
Noneotherwise.
>>> sort([38,16,27])
[1,2,0]
>>> permute(sort([38,49,16,27]), [38,49,16,27])
[16,27,38,49]
>>> sort([1, 13, 4, 17, 6, 23, 9])
[0, 2, 4, 6, 1, 3, 5]
>>> sort([0, 17, 4, 21, 8, 25, 12, 29, 16, 3, 20, 7, 24, 11, 28,\
15, 2, 19, 6, 23, 10, 27, 14, 1, 18, 5, 22, 9, 26, 13])
[0, 23, 16, 9, 2, 25,18, 11, 4, 27, 20, 13, 6, 29, 22,
15, 8, 1, 24, 17, 10, 3, 26, 19, 12, 5, 28, 21, 14, 7]
-
Implement a function
-
In this problem you will implement a secure and correct multiplication algorithm by using an untrusted, unreliable third-party web service to perform the actual multiplication. The web service consists of a PHP script at
http://cs-people.bu.edu/lapets/235/unreliable.php(e.g., the result of ((2 ⋅ 3 ⋅ 4) mod 7) can be obtained athttp://cs-people.bu.edu/lapets/235/unreliable.php?n=7&data=2,3,4). You can use the Python function below to invoke this script (this Python code needs to run on a computer connected to the internet).To test your code on a service that does not sometimes return incorrect answers, you can also use the URL
def unreliableUntrustedProduct(xs, n):
url = 'http://cs-people.bu.edu/lapets/235/unreliable.php'
return int(urlopen(url+"?n="+str(n)+"&data="+",".join([str(x) for x in xs])).read().decode())
http://cs-people.bu.edu/lapets/235/reliable.php.-
Implement a function
privateProduct(xs, p, q)that takes three inputs: a non-empty list of integersxs, a primep, and another distinct primeq. The function must compute the product modulopof all the integers in the listxs(assuming the web service performs its job correctly, which it may sometimes not do):
However, your implementation may not multiply any of the integers inprivateProduct(xs, p, q)= (xs[0] * xs[1] * ... * xs[len(xs)-1]) % pxson its own; it must useunreliableUntrustedProduct()to do so, and at the same time it must not send the actual integers inxsover the web or reveal them to the web service. Your implementation should leak no information about the entries inxsor the product obtained by multiplying them to anyone (unless they can solve an intractable problem in modular arithmetic).To solve this problem, use the extra primeqto create public and private RSA keys, and then encrypt all the integers inxs(you will need to encrypt them moduloninstead of modulopbecause RSA needs a composite modulus). Next, useunreliableUntrustedProduct()to compute the product of the RSA-encrypted integers modulon(i.e., take advantage of this isomorphism as in this homomorphic encryption example). Finally, yourprivateProduct()implementation should decrypt the result and return the product modulop. -
Implement a function
validPrivateProduct(xs, p, q)that takes three inputs: a non-empty list of integersxs, a primep, and another distinct primeq. The function must always correctly compute the product modulopof all the integers in the listxs:
As before, your implementation may not multiply any of the integers invalidPrivateProduct(xs, p, q)= (xs[0] * xs[1] * ... * xs[len(xs)-1]) % pxson its own; it must useunreliableUntrustedProduct()to do so, and at the same time it must not send the actual integers inxsover the web or reveal them to the web service.Start with your solution to part (a) and extend it by choosing a random valuerin ℤ/qℤ. For each integerxs[i]in the list, convert the pair(xs[i], r)into a value in ℤ/nℤ via the CRT isomorphism. Then encrypt all these ℤ/nℤ values using RSA and useunreliableUntrustedProduct()to compute their product. Finally, yourvalidPrivateProduct()implementation should decrypt the result and convert it back to an answer modulopvia the opposite direction of the CRT isomorphism.To check if the answer you obtained fromunreliableUntrustedProduct()is actually correct, determine whether the decrypted value moduloqhas the expected value (i.e., is it reallyrlen(xs)moduloq). If this check fails, keep repeating the entire process from the beginning until it succeeds.
-
Implement a function
-
Implement a function
isomorphism(A, B)that takes two tuplesAandBas inputs. Each tuple consists of two entries: the first is an ordered list of elements from an algebraic structure, and the second is a function on elements of that binary structure. Thus, the tupleArepresents an algebraic structure (A, ⊕), and the tupleBrepresents an algebraic structure (B, ⊗). You may assume that the list of elements is closed under the operation represented by the function. You may also assume that the bijection between the sets A and B is already provided by the order of the elements in each list (i.e., the ith entry in the first list corresponds to the ith entry in the second). Theisomorphism()function should returnTrueif there is indeed an isomorphism between (A, ⊕) and (B, ⊗), andFalseotherwise.
>>> plusMod2 = lambda x,y: (x + y) % 2
>>> A = ([0,1], plusMod2)
>>> B = ([C(0,2), C(1,2)], permute)
>>> isomorphism(A, B)
True
>>> plusMod4 = lambda x,y: (x + y) % 4
>>> multMod8 = lambda x,y: (x * y) % 8
>>> A = ([0,1,2,3], plusMod4)
>>> B = ([1,3,5,7], multMod8)
>>> isomorphism(A, B)
False
- Extra credit: In a comment, explain why there cannot be an isomorphism between (ℤ/4ℤ, +) and ((ℤ/8ℤ)*, ⋅), even though the two sets are the same size because |(ℤ/8ℤ)*| = φ(8) = 23 − 22 = 4 = |ℤ/4ℤ|.
[link] 5.5. Isomorphisms and Linear Equations of Congruence Classes
| ≅ |
|
| ≅ |
|
| ≅ |
| ≅ |
|
| = |
| = |
| = |
|
| = |
| |||
| = |
|
| ≡ |
|
Note that if g ≡ gcd(n,m) and b ∈ closure({g}, +), we have:
| = |
| |||
| = |
| |||
| = |
| |||
| ≡ |
|
| = |
|
| = |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
[link] 5.6. Isomorphisms and the Chinese Remainder Theorem
| = |
|
|
|
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| = |
|
| ℤ/2ℤ × ℤ/3ℤ | ℤ/6ℤ |
| (0,0) | 0 |
| (0,1) | 4 |
| (0,2) | 2 |
| (1,0) | 3 |
| (1,1) | 1 |
| (1,2) | 5 |
|
|
|
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| = |
|
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| = |
|
| = |
| |||
| = |
|
| = |
| |||
| = |
|
| = |
|
| ≡ |
| |||
| ≡ |
|
| = |
| |||
| = |
|
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| ||||||||||
| ≡ |
|
| ≡ |
| ||||||||||
| ≡ |
| |||||||||||
| ≡ |
|
| ≡ |
| ||||||||||
| ≡ |
| ||||||||||
| ≡ |
|
| ≡ |
|
| greatest common divisor algorithm |
Fermat's little theorem |
Euler's theorem |
||||
| ⇑ | ⇑ | ⇑ | ||||
| Bézout's identity |
⇐ | extended Euclidean algorithm |
⇐ | algorithm for finding multiplicative inverses |
⇒ | Euler's totient function φ |
| ⇑ | ||||||
| Chinese remainder theorem |
⇐ | CRT solver for two equations |
⇑ | |||
| linear congruence theorem |
⇐ | general CRT solver for two equations |
⇑ | |||
| induction | ⇐ | general CRT solver for n equations |
| formula for 3+4ℤ primes |
⇐ | square roots modulo p |
⇑ | |||
| Hensel's lemma | ⇐ | square roots modulo pk |
⇑ | |||
| CRT solver for two equations |
⇐ | square roots modulo n ⋅ m |
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
| ≡ |
|
[link] 5.7. Abstract Algebraic Structures and Axioms
Algebraic structures can be categorized according to the additional algebraic properties they possess. In this section we introduce terminology for several common types of algebraic structure.In other words, a set A is a magma under operator ⊕ if:
- A is closed under ⊕ (i.e., for all x, y ∈ A, x ⊕ y ∈ A).
- A is closed under ⊕;
- ⊕ is associative on A (for all x,y,z ∈ A, the equation (x ⊕ y) ⊕ z = x ⊕ (y ⊕ z) is true).
- A is closed under ⊕;
- ⊕ is associative on A;
- A contains an identity (which we call 1) in A (where for all x ∈ A, the equations 1 ⊕ x = x and x ⊕ 1 = x are always true).
"" be the empty string. Then (S, +) is an algebraic structure that is a monoid because string concatenation is associative and "" is the identity with respect to string concatenation.
[] be the empty list. Then (L, +) is an algebraic structure that is a monoid because list concatenation is associative and [] is the identity with respect to list concatenation.
- A is closed under ⊕;
- ⊕ is associative on A;
- A contains an identity;
- A has inverses with respect to ⊕ (for all x ∈ A, there exists x-1 ∈ A such that x ⊕ x-1 = 1 and x-1 ⊕ x = 1 are always true).
- A is closed under ⊕;
- ⊕ is associative on A;
- A contains an identity;
- A has inverses with respect to ⊕;
- ⊕ is commutative on A (i.e., for all x,y ∈ A, the equation x ⊕ y = y ⊕ x is always true).
- Sn is closed under composition of permutations (since Sn contains all of them);
- composition of functions (including permutations) is associative;
- there is an identity permutation [0,1,2,3,4,5,...,n-1];
- every permutation p ∈ Sn has an inverse p-1 ∈ Sn such that p o p-1 = [0,1,...,n-1].
def op(x, y):
return [x, y];
>>> op(1,2) == op(2,1)
False
>>> op(1,op(2,3)) == op(op(1,2),3)
False
def op(x, y):
return {x, y};
>>> op(1,2) == op(2,1)
True
>>> op(3,op(1,2)) == op(op(2,1),3)
True
>>> op(1,op(2,3)) == op(op(1,2),3)
False
def op(x, y):
return x + y # List concatenation done using +.
[].
>>> op([1],op([2],[3])) == op(op([1],[2]),[3])
True
>>> op([1],op([2],[3])) == op(op([1],[2]),[3])
True
>>> op([], [1,2,3]) == [1,2,3]
True
- x ∈ A1, where A1 is a free magma;
- x ∈ A2, where A2 is a monoid;
- x ∈ A3, where A3 is a group and has an element y ∈ A3 s.t. y ⊕ x takes much less space to store than x;
- x ∈ A4, where A4 is a commutative semigroup.
- an element of a free magma is a binary tree in which every node has ordered children, so for any node whose children we want to store separately, we would need a unique pair of ordered identifiers for each child subtree;
- an element x in a monoid is assembled using an associative operation, and we would not need to store anything about the grouping/hierarchization of the individual generators found in an element x, so it would be sufficient to use an integer to represent each separate portion (reassembly would involve sorting the pieces in ascending order by the integer associated with them, and then gluing them back together using the associative operation);
- whenever we need to store a copy of x, we should instead store y ⊕ x and return y-1 ⋅ (y ⋅ x) = x to the user when we need to retrieve the stored element;
- since a commutative semigroup's operation is both associative and commutative, we can group all the like generators in x together and simply store how many of each there are (for example, if x = abaabbacc, we would only store 4a3b2c).
| abstract algebraic structure | concrete data structure |
| element in set of generators S | individual character, string, or data object |
| set of generators S | base cases; alphabet; data containers |
| operator ⊕ | constructor for node with children; operator/function/method on data items |
| element in closure of S under ⊕ | individual data object |
| closure of S under ⊕ | set of all possible data objects |
| magma | commutative magma |
semigroup | commutative semigroup |
monoid | group | abelian group |
|
| typical data structures |
binary trees under node constructor |
binary trees with unordered branches under node constructor |
lists with list concatenation; strings with string concatenation |
sets with duplicates |
lists with list concatenation and empty list; strings with string concatenation and empty string |
||
| distributed computation |
must operate on data in its original ordering and hierarchization |
must operate on data in its original hierarchization |
must operate over original ordering |
can operate on data in any order |
can employ identity as a base case; can ignore identity entries |
can "cancel" pairs of adjacent inverses |
can "cancel" all elements that can be paired with an inverse |
| distributed storage |
must store original ordering and hierarchization |
must store original hierarchization |
must store original ordering | can store in any order |
no need to store identities |
||
| compression | common subtrees | common hierarchies | run-length encoding | distinct elements with quantities |
can ignore identity entries |
can "cancel" pairs of adjacent inverses; can apply invertible transformations |
can "cancel" all elements that can be paired with an inverse |
| example/ test case enumeration |
can enumerate examples/test cases automatically | ||||||
| proving implementation works correctly for all inputs |
can show this by structural induction | ||||||
- ℕ is closed under max
- max is associative on ℕ
- max is commutative on ℕ
| = |
|
- if gcd(n,m) = 1, then (a, n) ⊕ (b, m) = (c, (n ⋅ m)) where c is the unique solution
to the system of equations:
c ≡ a (mod n) c ≡ b (mod m) - if gcd(n,m) ≠ 1, then (a, n) ⊕ (b, m) = unknown;
- for any (a,n) ∈ A, unknown ⊕ (a, n) = unknown;
- for any (a,n) ∈ A, (a, n) ⊕ unknown = unknown.
-
The generating set G = {∅, {1}, {2}, {3}} with the union operation ∪ as the binary operator.
We know that closure(G, ∪) is the set of subsets of {1,2,3}:
Thus, we know from set theory that the union operation on sets is associative and commutative. There is an identity element ∅. There are no inverses.closure(G, ∪) = {∅, {1}, {2}, {3}, {1,2}, {2,3}, {1,3}, {1,2,3}} -
For positive integers a,n ∈ ℕ where gcd(a,n) = 1, generating set G = {a} with integer addition modulo n.
The closure is the entire set {0,..., n − 1} because:
Integer addition modulo n is associative and commutative, has identity 0, and for every x ∈ ℤ/nℤ, the inverse is n-x ∈ ℤ/nℤ.{a, a + a, a + a + a, ..., a + ... + a} = {(i ⋅ a) mod n | i ∈ {1 ,..., n}}
[link] 5.8. Subgroups and the Hidden Subgroup Problem
If we look at subsets of the elements in a group, we might find that certain subsets are closed under the operator for that group. These subsets are called subgroups, and the concept of a subgroup can be very useful when studying and using groups.- {0}, because all terms of the form 0, 0+0, 0+0+0, and so on are equivalent to 0;
- {0,2}, since closure({0,2}, +) = {0,2};
- {0,1,2,3} = ℤ/4ℤ.
- {0}, because all terms of the form 0, 0+0, 0+0+0, and so on are equivalent to 0;
- {0,2,4}, since closure({2}, +) = closure({0,2,4}, +) = {0,2,4};
- {0,3}, since closure({3}, +) = closure({0,3}, +) = {0,3};
- {0,1,2,3,4,5} = closure({1}, +) = ℤ/6ℤ.
- ({0,2,4}, +) ≅ (ℤ/(6/2)ℤ) ≅ (ℤ/3ℤ, +);
- ({0,3}, +) ≅ (ℤ/(6/3)ℤ) ≅ (ℤ/2ℤ, +).
- finding a non-trivial subgroup of (ℤ/nℤ, +);
- finding a non-trivial subgroup of ((ℤ/nℤ)*, ⋅).
- Shor's algorithm: n ∈ ℕ
-
- while r is odd or a(r/2) ≡ −1 (mod n)
- choose a random a ∈ ℤ/nℤ
- if gcd(a, n) > 1, return gcd(a, n)
- otherwise, find the smallest r > 0 such that ar ≡ 1 (mod n)
- since we have exited the loop, then r is even and a(r/2) ≢ −1 (mod n)
- thus, a(r/2) is a non-trivial root of ar
- return gcd(a(r/2) ± 1, n), which is a non-trivial factor by this fact
- while r is odd or a(r/2) ≡ −1 (mod n)
|
| ≡ |
|
| ≡ |
|
| = |
| |||
| = |
|
[link] 5.9. Structural Induction and Direct Product of Algebraic Structures
Suppose an algebraic structure A with operator ⊕ has a generating set. Since any element in A must be either a genrator or some finite number of generators combined using the operator ⊕, we can use induction to prove facts (i.e., true formulas) about all the elements in A.
| ≅ |
|
| = |
|
| = |
|
| ||||||
| = |
|
| ||||||
| = |
|
|
[link] 5.10. Assignment #6: Generalized CRT, Data Structures, and More Isomorphisms
hw6.py (submitted to the location hw6/hw6.py). Please follow the gsubmit directions.
For the programming parts, you may import the following library functions in your module (you may not need all these functions for this assignment depending on how you approach the problems, but they may be used):
from math import floor
from fractions import gcd
from random import randint
-
Solve the following equations using step-by-step equational reasoning, and list each step.
-
Solve the following system of equations and find a unique congruence class solution (including the set of congruence classes from which the congruence class is drawn) if it exists; if no solution exists, explain why not:
x ≡ 7 (mod 21) x ≡ 21 (mod 49) -
Solve the following system of equations and find a unique congruence class solution if it exists; if no solution exists, explain why not:
x ≡ 11 (mod 14) x ≡ 18 (mod 21) -
Solve the following system of equations and find all congruence class solutions if any exist; if no solution exists, explain why not:
x2 ≡ 4 (mod 35) 3 ⋅ x ≡ 15 (mod 21) -
Solve the following system of equations and find a unique congruence class solution if it exists; if no solution exists, explain why not:
x ≡ 10 (mod 12) x ≡ 2 (mod 16) - Suppose that you have a standard 12-hour analog clock. You also have an alarm that rings every 16 hours. At some point in the last two days, the alarm rang at exactly midnight. At this moment, the analog clock reads 6 (you do not know if it is AM or PM), and it has been 14 hours since the alarm last rang. How many hours have passed since the alarm rang at exactly midnight, and what time is it? Set up an appropriate equation or system of equations and use step-by-step equational reasoning to find the solution.
-
Bob needs to reserve virtual machines on a cloud computing service to solve a number of problems before a deadline. He has two options: reserve some number of virtual machines that can each solve 12 problems before the deadline, or reserve some number of virtual machines that can each solve 15 problems before the deadline:
- with virtual machines that can each solve 12 problems, Bob will end up using all the virtual machines to their full capacity except one, which will have only 1 problem to solve;
- with virtual machines that can each solve 15 problems, Bob will end up using all the virtual machines to their full capacity except one, which will have only 7 problems to solve.
- Assuming that Bob has at most 60 problems to solve, how many problems does Bob have?
- If Bob can only reserve batches of machines that all have the same capacity (capacities are always 2 or greater), and the the fastest machine can only solve 19 problems before the deadline, is there anything Bob can do to avoid having at least one machine not used to its full capacity?
-
Solve the following system of equations and find a unique congruence class solution (including the set of congruence classes from which the congruence class is drawn) if it exists; if no solution exists, explain why not:
-
Implement the following Python functions for solving systems of equations involving congruence classes.
-
Implement a function
solveOne(c, a, m)that takes three integersc,a, andm≥ 1. If it exists, the function should return the solution x ∈ {0, ...,m-1} to the following equation:
If no solution exists, the function should returnc⋅ x≡ a(modm)None. The function must work correctly for all possible equations (you should use the linear congruence theorem).
>>> solveOne(1, 2, 3)
2
>>> solveOne(3, 4, 7)
6
>>> solveOne(1, 5, 11)
5
>>> solveOne(2, 3, 8)
None
>>> solveOne(6, 2, 8)
3
-
Implement a function
solveTwo(e1, e2)that takes two tuplese1ande2as inputs, each of the form(c, a, m)(i.e., containing three integer elements). Each tuple(c, a, m)corresponds to an equation of the form:
Thus, the two tuples, if we call themc⋅ x≡ a(modm)(c, a, m)and(d, b, n), correspond to a system of equations of the form:
The functionc⋅ x≡ a(modm)d⋅ x≡ b(modn)solveTwo()should return the unique solution x to the above system of equations. If either equation cannot be solved usingsolveOne(), the function should returnNone.
>>> solveTwo((3, 4, 7), (1, 5, 11))
27
>>> solveTwo((1, 1, 6), (1, 3, 8))
19
>>> solveTwo((1, 0, 6), (1, 3, 8))
None
-
Implement a function
solveAll(es)that takes a list of one or more equations, each of the form(c, a, m). The function should return the unique solution x to the system of equations represented by the list of equations. If the system of equations has no solution, the function should returnNone.
>>> solveAll([(1,2,3)])
2
>>> solveAll([(3,4,7), (1,5,11)])
27
>>> solveAll([(5,3,7), (3,5,11), (11,4,13)])
856
>>> solveAll([(1,2,3), (7,8,31), (3,5,7), (11,4,13)])
7109
>>> solveAll([(3,2,4), (7,8,9), (2,8,25), (4,4,7)])
554
>>> solveAll([(1, 1, 6), (1, 3, 8)])
19
>>> solveAll([(1, 0, 6), (1, 3, 8)])
None
-
Implement a function
-
Suppose you are given the following function (which simulates the component of Shor's algorithm that can run efficiently on a quantum computer). Given n ∈ ℕ and a ∈ ℤ/nℤ, it returns the smallest non-zero congruence class r ∈ ℤ/φ(n)ℤ such that ar ≡ 1 (mod n).
Implement a function
def quantum(a, n):
return [pow(a,k,n) for k in range(1,n)].index(1) + 1
factor(n)that finds a non-trivial factor of a composite number inputnby callingquantum(). Solutions that use exhaustive search will receive no credit. -
In this problem you will implement a reliable addition algorithm for ℤ/256ℤ by using an unreliable addition algorithm for ℤ/256ℤ. You may not use the addition operator
+anywhere in your solutions to this problem. You may assume you are given access to a functionplus256unreliable(x, y)that returns an answer that is at most 4 away from the true sum modulo256(assume there is no chance of this error causing the answer to wrap around):
You may use the following Python simulation of this unreliable function in order to test your code:| plus256unreliable(x, y)− ((x + y) % 256) |< 4
from random import randint
def plus256unreliable(x, y):
r = randint(0,7) - 4
return (min(255, max(0, ((x + y)%256) + r)))
-
Implement a Python function
plus16(x, y)that reliably returns(x + y) % 16with 100% accuracy. You may use//,*,plus256unreliable(), and numerical constants, but you may not use anything else in your definition. Hint: you can callplus256unreliable()more than once. -
Implement a Python function
plus256(x, y)that reliably returns(x + y) % 256with 100% accuracy. Your solution must usesolveAll(), and you are allowed to use%, but you may not use the addition or subtraction operators: choose four appropriate prime or mutually coprime moduli, perform the addition operations modulo those moduli, then restore the original result usingsolveAll().
-
Implement a Python function
-
Extra credit: Suppose you are working with a commutative magma (A, ⊕) where the set of elements is A = closure({a, b, c, d, e, f, g}, ⊕) and the commutative (but not associative) operator is ⊕. Add the following functions to your Python file; the first function implements the operator, and the second function randomly rearranges the elements in a given array.
def oplus(x, y):
return (x, y)
from random import shuffle
def rearrange(l):
r = l[:]
shuffle(r)
return r
-
Implement a Python function
decompose()that decomposes a given element in the algebra into a list in which each generator from {a, b, c, d, e, f, g} that occurs in the input element is paired with exactly one integer. The integer should be chosen so thatreassemble()below can work correctly. Your output should look something like the following (the full output is not revealed as it is part of the problem):
>>> oplus(oplus("a", "b"), "c")
(("a","b"), "c")
>>> decompose(oplus(oplus("a", "b"), "c"))
[("a", ???), ("b", ???), ("c", ???)]
-
Implement a Python function
reassemble()that takes a randomly rearranged output fromdecompose()and reassembles an equivalent element within the algebraic structure.
>>> rearrange([("a", ???), ("b", ???), ("c", ???)])
[("c", ???), ("a", ???), ("b", ???)]
>>> reassemble([("c", ???), ("a", ???), ("b", ???)])
(("a","b"), "c")
-
Implement a Python function
-
Extra extra credit: The group S2 ≅ C2 ≅ ℤ/2ℤ is the only group containing two elements; there is no way to build a group containing two elements that is not isomorphic to these. Likewise, C3 ≅ ℤ/3ℤ is the only group containing three elements. Both of these groups are cyclic.The smallest possible non-cyclic group is called the Klein group, and is defined to be V = (closure({a, b, c}, ⊕), ⊕), where a is an identity and:
Note that V is a group, so b ⊕ c = c ⊕ b. Determine how many distinct elements there are in the group (i.e., provide an exhaustive set of distinct elements and informally or formally explain why all possible terms involving ⊗, a, b, and c must equal one of these elements).b ⊕ b = a c ⊕ c = a (b ⊕ c) ⊕ (b ⊕ c) = a
[link] Review #2. Algebraic Structures and their Properties
This section contains a comprehensive collection of review problems going over all the course material. Many of these problems are an accurate representation of the kinds of problems you may see on an exam.
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
|
|
| ≡ |
|
| ≡ |
|
| ≡ |
| |||
| ≡ |
|
| ∈ |
| |||
| ∈ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ∈ |
| |||
| ∈ |
|
| ≡ |
| |||
| ≡ |
| |||
| ≡ |
| |||
| ∈ |
| |||
| ∈ |
|
| ∈ |
|
| ≡ |
|
-
Consider the following two circular shift permutations:
How many of each would you need to compose to obtain the permutation [9,0,1,2,3,4,5,6,7,8]?[8,9,0,1,2,3,4,5,6,7] [5,6,7,8,9,0,1,2,3,4] These permutations specified are in C10, and we know that C10 ≅ ℤ/10ℤ. Notice that [8,9,0,1,2,3,4,5,6,7] ∈ C10 can correspond to 8 ∈ ℤ/10ℤ, that [5,6,7,8,9,0,1,2,3,4] ∈ C10 can correspond to 5 ∈ ℤ/10ℤ, and that [9,0,1,2,3,4,5,6,7,8] ∈ C10 can correspond to 9 ∈ ℤ/10ℤ. By Bézout's identity we have that:
Thus, we would need to compose 8 instances of the first permutation and 3 instances of the second permutation to obtain [9,0,1,2,3,4,5,6,7,8].8 ⋅ 2 + 5 ⋅ (-3) = 1 8 ⋅ 2 + 5 ⋅ 7 ≡ 1 (mod 10) 8 ⋅ (9 ⋅ 2) + 5 ⋅ (9 ⋅ 7) ≡ 9 ⋅ 1 (mod 10) 8 ⋅ 8 + 5 ⋅ 3 ≡ 9 (mod 10) -
Rewrite the permutation [3,4,0,1,2] as a composition of adjacent swap permutations.
We can simply run the bubble sort algorithm on the above permutation and record the permutation that represents each swap. This leads to the following sequence:
Thus, by applying the above sequence of permutations to [0,1,2,3,4] in reverse order, we can obtain [3,4,0,1,2], so the factorization of [3,4,0,1,2] into adjacent swap permutations is:p1 = [0,2,1,3,4] p2 = [0,1,3,2,4] p3 = [0,1,2,4,3] p4 = [1,0,2,3,4] p5 = [0,2,1,3,4] p6 = [0,1,3,2,4] [3,4,0,1,2] = p1 o p2 o p3 o p4 o p5 o p6 o [0,1,2,3,4]
- a single exponentiation operation modulo 21 takes 213 = 9261 steps;
- a single exponentiation operation modulo 3 takes 33 = 27 steps;
- a single exponentiation operation modulo 7 takes 73 = 343 steps;
- an exponentiation operation modulo 3 and an exponentiation operation modulo 7 together take 343 + 27 = 370 steps;
- solving a two-equation system for two values, a modulo 3 and b modulo 7, takes 8000 steps using CRT;
- we can either compute the exponentiation sequence directly modulo 21, or we can split it into two sequences of computations (one modulo 3, the other modulo 7) and then recombine using CRT at the end.
-
What is the number of steps needed to perform k exponentiations modulo 21?
f(k) = 9261 ⋅ k -
What is the number of steps needed to perform k exponentiations modulo 3 and k exponentiations modulo 7, then to recombine using CRT?
f(k) = 370 ⋅ k + 8000
-
Explain why the following polynomial has no integer solutions (Hint: you only need to evaluate the polynomial for two possible values of x):
x4 + x2 + 3 = 0 If the above equation has an integer solution x, then it must have an integer solution modulo 2, since we can take the modulus of both sides:
Thus, we have using logic that:x4 + x2 + 3 = 0 (x4 + x2 + 3) mod 2 = 0 mod 2 x4 + x2 + 3 ≡ 0 (mod 2)
Note that this only works in one direction. A solution modulo 2 does not necessarily imply that there is an integer solution.(exists solution in ℤ) → (exists solution modulo 2) (no solution modulo 2) → (no solution in ℤ)
We see that for x = 0 and x = 1, the left-hand side is odd. The right-hand side is 0, so it is always even. Thus, no integer solution exists. -
Find at least one solution x ∈ ℤ/10ℤ to the following system of equations (you must use Bézout's identity):
6 ⋅ y + 5 ⋅ x - 1 ≡ 0 (mod 10) x2 ≡ y (mod 10) Since 5 and 6 are coprime, we can find a solution to the first equations. One such solution is:
We also have that 92 ≡ 81 ≡ 1 (mod 10). Thus, since 12 ≡ 1 (mod 10), both equations are satisfied by this solution.y ≡ 1 (mod 10) x ≡ -1 (mod 10) ≡ 9 (mod 10)
-
Suppose you want to send some s ∈ ℤ/nℤ to Alice and Bob, but you want to ensure that the only way Alice and Bob can retrieve s is if they work together. What two distinct pairs (s1, p1) and (s2, p2) would you send to Alice and Bob, respectively, so that they would need to work together to recover s?
You would need to send (s mod p, p) to Alice and (s mod q, q) to Bob where s < p ⋅ q and p and q are distinct and coprime.
-
Suppose Bob is generating a public RSA key; he chooses a very large prime p, and then he chooses q = 2. Why is this not secure?
Bob must share his public key (n, e). Since n = p ⋅ 2, n is even. This can immediately be seen by looking at the last bit of n (which will be 0, since n mod 2 = 0). It is then easy to recover the secret value p.
-
Suppose Alice and Bob use Shamir secret sharing to share a password s to a lock that is not protected from brute force attacks (i.e., anyone can keep trying different passwords until they unlock it). Alice holds s mod p and Bob holds s mod q, where s < p ⋅ q. However, suppose that Bob happens to be using q = 2, and Alice knows this. What can Alice do to quickly break the lock?
If Alice holds a and Bob holds b, the system of equations that would be set up to recover s is as follows:
Notice that there are only two possibilities for Bob's value b ∈ ℤ/2ℤ. Thus, Alice could set up two systems, one for b = 0 and another for b = 1, solve both, and try both secrets s on the lock.x ≡ a (mod p) x ≡ b (mod 2)
- Alice: nAlice = 3 and (s mod 3) = 2
- Bob: nBob = 4 and (s mod 4) = 3
- Carl: nCarl = 5 and (s mod 5) = 2
- Dan: nDan = 7 and (s mod 7) = 4
-
Which participant's stored value s mod n has Eve sabotaged?
Any two participants can recover the secret s by setting up a system with two equations and solving the system using CRT. We list all of the possible combinations and solve for s to find which participant's value has been corrupted.
- Alice and Bob:
s ≡ 2 (mod 3) s ≡ 3 (mod 4) s ≡ 11 (mod 12) - Alice and Carl:
s ≡ 2 (mod 3) s ≡ 2 (mod 5) s ≡ 2 (mod 15) - Alice and Dan:
s ≡ 2 (mod 3) s ≡ 4 (mod 7) s ≡ 11 (mod 21) - Bob and Carl:
s ≡ 3 (mod 4) s ≡ 2 (mod 5) s ≡ 7 (mod 20) - Bob and Dan:
s ≡ 3 (mod 4) s ≡ 4 (mod 7) s ≡ 11 (mod 28) - Carl and Dan:
s ≡ 2 (mod 5) s ≡ 4 (mod 7) s ≡ 32 (mod 35)
- Alice and Bob:
-
What is the correct secret value s?
Since three of the six possible pairings result in s = 11, and the other three are inconsistent and all involve Carl, it must be that s = 11 was the original uncorrupted secret.
-
What's the number of different shared secret values these four participants can store (assuming they use the same moduli, and require that any two members should be able to recover the secret).
Since any two participants must be able to recover s, it must be that s < n ⋅ m for every possible pair n and m. The smallest two values are 3 and 4, so 3 ⋅ 4 - 1 = 11, where 11 ∈ ℤ/(3 ⋅ 4)ℤ, is the largest possible s that can be receovered.
-
Suppose you want to store an n-bit number s. You want to store it in a way that makes it possible to recover s even if one of the bits is corrupted. How can you accomplish this using at most approximately 2 ⋅ n bits?
Choose four distinct coprime numbers m1, m2, m3, and m4 such that s is less than the product of every pair of these, but such that the product of any pair is not much larger than s (e.g., m1 and m2 can be stored in the same number of bits as s). Then store (s mod m1, s mod m2, s mod m3, s mod m4) using about 2 ⋅ n bits.
If any individual bit is corrupted, this corrupts at most one of the four values stored. As with Alice, Bob, and Dan, the original value can still be recovered.
[link] Appendix A. Using gsubmit
In this course, you will submit your assignments usinggsubmit. This section reproduces and extends some of the instructions already made available by the BU Computer Science Department.[link] A.1. Register for a CS account
You must obtain a CS account to use thecsa machines maintained by the CS Dept. You will need to physically visit the undergraduate computing lab located at 730 Commonwealth Avenue, on the third floor in room 302.[link] A.2. Download SSH/SCP client software
You will need an SCP or SFTP client (such as WinSCP for Windows or CyberDuck for OS X) to copy files from your local computer to yourcsa home directory. If you are using Windows, you will also need an SSH client (such as PuTTY).[link] A.3. Submitting assignments using gsubmit
A typical workflow can be described as follows.- You assemble your assignment solution file(s) on your own computer or device.
local
devicehw1 hw1.py your csa2/csa3
home directoryyour gsubmit
directory for CS 235 -
You log into
csa2orcsa3using an SCP or SSH client and create a directory for your submission in your CS account home directory. Note that in the examples below%>represents a terminal prompt, which may look different on your system.
%> cd ~
%> mkdir hw1
local
devicehw1 hw1.py your csa2/csa3
home directoryhw1
your gsubmit
directory for CS 235 -
If you have not already done so (e.g., if you were using an SSH client in the previous step), you log into
csa2orcsa3using an SCP client and copy your completed file(s) into that directory.local
devicehw1 hw1.py ⇒ your csa2/csa3
home directoryhw1 hw1.py your gsubmit
directory for CS 235 -
If you have not already done so, you log into
csa2orcsa3using an SSH client and run thegsubmitcommands to copy the files from your CS account home directory to thegsubmitdirectories to which the course staff has access.
%> cd ~
%> gsubmit cs235 hw1
local
devicehw1 hw1.py ⇒ your csa2/csa3
home directoryhw1 hw1.py ⇒ your gsubmit
directory for CS 235hw1 hw1.py -
To view your submitted files, you can use the following command:
To look at a file that has already been submitted, you can use:
%> gsubmit cs235 -ls
After grades are posted (normally, this will be announced on the mailing list and in lecture), you can check your grade using:
%> gsubmit cs235 -cat hw1/hw1.py
%> gsubmit cs235 -cat grade.hw1.txt
[link] Appendix B. Python
The Python programming language will be among the languages we use in this course. This language supports the object-oriented, imperative, and functional programming paradigms, has automatic memory managememt, and natively supports common high-level data structures such as lists and sets. Python is often used as an interpreted language, but it can also be compiled.[link] B.1. Obtaining Python
The latest version of Python 3 can be downloaded at: https://www.python.org/downloads/. In this course, we will require the use if Python 3, which has been installed on all the CS Department's undergraduate computing lab machines, as well as oncsa2/csa3.[link] B.2. Assembling a Python module
The simplest Python program is a single file (called a module) with the file extension.py. For example, suppose the following is contained within a file called example.py:
# This is a comment in example.py.
# Below is a Python statement.
print("Hello, world.")
python3, python3.2, python3.3, etc. depending on the Python installation you're using). Note that in the examples below %> represents a terminal prompt, which may look different on your system.
%> python example.py
Hello, world.
%> python
Python 3.2 ...
Type "help", "copyright", "credits" or "license" for more information.
>>> exec(open("example.py").read()) # Load example.py module.
Hello, world.
>>> x = "Hello." # Execute an assignment statement.
>>> print(x) # Execute a print statement.
Hello.
>>> x # Evaluate a string expression.
'Hello.'
>>> 1 + 2 # Evaluate a numerical expression.
3
[link] B.3. Common data structures (i.e., Python expressions)
Python provides native support for several data structures that we will use throughout this course: integers, strings, lists, tuples, sets, and dictionaries (also known as finite maps). In this subsection, we present how instances of these data structures are represented in Python, as well as the most common operations and functions that can be applied to these data structure instances.-
Booleans consist of two constants:
TrueandFalse.- The usual logical operations are available using the operators
and,or, andnot.
>>> True # A boolean constant.
True
>>> False # A boolean constant.
False
>>> True and False or True and (not False) # A boolean expression.
True
- The usual logical operations are available using the operators
-
Integers are written as in most other programming languages (i.e., as a sequence of digits).
- The usual arithmetic operations are available using the operators
+,*,-, and/. The infix operator//represents integer division, and the infix operators**represents exponentiation. Negative integers are prefixed with the negation operator-. - The usual relational operators
==,!=,<,>,<=,>=are available. - The
int()function can convert a string that looks like an integer into an integer.
>>> 123 # An integer constant.
True
>>> 1 * (2 + 3) // 4 - 5 # An integer expression.
-4
>>> 4 * 5 >= 19 # A boolean expression involving integers.
True
>>> int("123") # A string being converted into an integer
123
- The usual arithmetic operations are available using the operators
-
Strings are delimited by either
'or"characters. Strings can be treated as lists of single-character strings. Another way to look at this is that there is no distinction between a character and a string: all characters are just strings of length 1. Multiline strings can be delimited using"""or'''(i.e., three quotation mark characters at the beginning and end of the string literal).- The empty string is denoted using
''or"". - Two strings can be concatenated using
+. - The function
len()returns the length of a string. - Individual characters in a string can be accessed using the bracketed index notation (e.g.,
s[i]). These characters are also strings themselves.
>>> 'Example.' # A string.
'Example.'
>>> "Example." # Alternate notation for a string.
'Example.'
>>> len("ABCD") # String length.
4
>>> "ABCD" + "EFG" # String concatenation.
'ABCDEFG'
>>> "ABCD"[2] # Third character in the string.
'C'
- The empty string is denoted using
-
Lists are similar to arrays: they are ordered sequences of objects and/or values. The entries of a list can be of a mixture of different types, and lists containing one or more objects are delimited using
[and], with the individual list entries separated by commas. Lists cannot be members of sets.- The empty list is denoted using
[]. - Two lists can be concatenated using
+. - The function
len()returns the length of a list. - Individual entries in a list can be accessed using the bracketed index notation (e.g.,
a[i]). - To check if a value is in a list, use the
inrelational operator.
>>> [1,2,"A","B"] # A list.
[1, 2, 'A', 'B']
>>> [1, 2] + ['A','B'] # Concatenating lists.
[1, 2, 'A', 'B']
>>> len([1,2,"A","B"] ) # List length.
4
>>> [1,2,"A","B"][0] # First entry in the list.
1
>>> 1 in [1, 2] # List containment check.
True
- The empty list is denoted using
-
Tuples are similar to lists (they are ordered, and can contain objects of different types), except they are delimited by parentheses
(and), with entries separated by commas. The main distinction between lists and tuples is that tuples are hashable (i.e., they can be members of sets).- The empty tuple is denoted using
(). - A tuple containing a single object
xis denoted using(x, ). - Two tuples can be concatenated using
+. - A tuple can be turned into a list using the
list()function. - A list can be turned into a tuple using the
tuple()function. - The function
len()returns the length of a tuple. - Individual entries in a tuple can be accessed using the bracketed index notation (e.g.,
t[i]). - To check if a value is in a tuple, use the
inrelational operator.
>>> (1,2,"A","B") # A tuple.
(1, 2, 'A', 'B')
>>> (1,) # Another tuple.
(1,)
>>> (1, 2) + ('A','B') # Concatenating tuples.
(1, 2, 'A', 'B')
>>> list((1, 2, 'A','B')) # A tuple being converted into a list.
[1, 2, 'A', 'B']
>>> tuple([1, 2, 'A','B']) # A list being converted into a tuple.
(1, 2, 'A', 'B')
>>> len((1,2,"A","B")) # Tuple length.
4
>>> (1,2,"A","B")[0] # First entry in the tuple.
1
>>> 1 in (1, 2) # Tuple containment check.
True
- The empty tuple is denoted using
-
Sets are unordered sequences that cannot contain duplicates. They are a close approximation of mathematical sets. Sets cannot be members of sets.
- The empty set is denoted using
set(). - The methods
.union()and.intersectcorrespond to the standard set operations. - A list or tuple can be turned into a set using the
set()function. - A set can be turned into a list or tuple using the
list()orlist()function, respectively. - The function
len()returns the size of a set. - To access individual entries in a set, it is necessary to turn the set into a list or tuple.
- To check if a value is in a set, use the
inrelational operator.
>>> {1,2,"A","B"} # A set.
{1, 2, 'A', 'B'}
>>> ({1,2}.union({3,4})).intersection({4,5}) # Set operations.
{4}
>>> set([1, 2]).union(set(('A','B'))) # Converting a list and a tuple to sets.
{'A', 1, 2, 'B'}
>>> len({1,2,"A","B"}) # Set size.
4
>>> 1 in {1,2,"A","B"} # Tuple containment check.
True
- The empty set is denoted using
-
Frozen sets are like sets, except they can be members of other sets. A set can be turned into a frozen set using the
frozenset()function.
>>> frozenset({1,2,3}) # A frozen set.
frozenset({1, 2, 3})
>>> {frozenset({1,2}), frozenset({3,4})} # Set of frozen sets.
{frozenset({3, 4}), frozenset({1, 2})}
-
Dictionaries are unordered collections of associations between some set of keys and some set of values. Dictionaries are also known as finite maps.
- The empty dictionary is denoted using
{}. - The list of keys that the dictionary associates with values can be obtained using
list(d.keys()). - The list of values that the dictionary contains can be obtained using
list(d.values()). - The function
len()returns the number of entries in the dictionary. - Individual entries in a dictionary can be accessed using the bracketed index notation (e.g.,
d[key]).
>>> {"A":1, "B":2} # A dictionary.
{'A': 1, 'B': 2}
>>> list({"A":1, "B":2}.keys()) # Dictionary keys.
['A', 'B']
>>> list({"A":1, "B":2}.values()) # Dictionary values.
[1, 2]
>>> len({"A":1, "B":2}) # Dictionary size.
2
>>> {"A":1, "B":2}["A"] # Obtain a dictionary value using a key.
1
- The empty dictionary is denoted using
[link] B.4. Function, procedure, and method invocations
Python provides a variety of ways to supply parameter arguments when invoking functions, procedures, and methods.-
Function calls and method/procedure invocations consist of the function, procedure, or method name followed by a parenthesized, comma-delimited list of arguments. For example, suppose a function or procedure
example()is defined as follows:To invoke the above definition, we can use one of the following techniques.
def example(x, y, z):
print("Invoked.")
return x + y + z
-
Passing arguments directly involves listing the comma-delimited arguments directly between parentheses.
>>> example(1,2,3)
Invoked.
6
-
The argument unpacking operator (also known as the
*-operator, the scatter operator, or the splat operator) involves providing a list to the function, preceded by the*symbol; the arguments will be drawn from the elements in the list.
>>> args = [1,2,3]
>>> example(*args)
Invoked.
6
-
The keyword argument unpacking operator (also known as the
**-operator) involves providing a dictionary to the function, preceded by the**symbol; each named paramter in the function definition will be looked up in the dictionary, and the value associated with that dictionary key will be used as the argument passed to that parameter.
>>> args = {'z':3, 'x':1, 'y':2}
>>> example(**args)
Invoked.
6
-
Passing arguments directly involves listing the comma-delimited arguments directly between parentheses.
-
Default parameter values can be specified in any definition. Suppose the following definition is provided.
The behavior is then as follows: if an argument corresponding to a parameter is not supplied, the default value found in the definition is used. If an argument is supplied, the supplied argument value is used.
def example(x = 1, y = 2, z = 3):
return x + y + z
>>> example(0, 0)
3
>>> example(0)
5
>>> example()
6
[link] B.5. Comprehensions
Python provides concise notations for defining data structures and performing logical computations. In particular, it support a comprehension notation that can be used to build lists, tuples, sets, and dictionaries.-
List comprehensions make it possible to construct a list by iterating over one or more other data structure instances (such as a list, tuple, set, or dictionary) and performing some operation on each element or combination of elements. The resulting list will contain the result of evaluating the body for every combination.
It is also possible to add conditions anywhere after the first
>>> [ x for x in [1,2,3] ]
[1, 2, 3]
>>> [ 2 * x for x in {1,2,3} ]
[2, 4, 6]
>>> [ x + y for x in {1,2,3} for y in (1,2,3) ]
[2, 3, 4, 3, 4, 5, 4, 5, 6]
forclause. This will filter which combinations are actually used to add a value to the resulting list.
>>> [ x for x in {1,2,3} if x < 3 ]
[1, 2]
>>> [ x + y for x in {1,2,3} for y in (1,2,3) if x > 2 and y > 1 ]
[5, 6]
-
Set comprehensions make it possible to construct a set by iterating over one or more other data structure instances (such as a list, tuple, set, or dictionary) and performing some operation on each element or combination of elements. The resulting list will contain the result of evaluating the body for every combination. Notice that the result will contain no duplicates because the result is a set.
>>> { x for x in [1,2,3,1,2,3] }
{1, 2, 3}
-
Dictionary comprehensions make it possible to construct a dictionary by iterating over one or more other data structure instances (such as a list, tuple, set, or dictionary) and performing some operation on each element or combination of elements. The resulting dictionary will contain the result of evaluating the body for every combination.
>>> { key : 2 for key in ["A","B","C"] }
{'A': 2, 'C': 2, 'B': 2}
[link] B.6. Other useful built-in functions
The built-in functiontype() can be used to determine the type of a value. Below, we provide examples of how to check whether a given expression has one of the common Python types:
>>> type(True) == @bool
True
>>> type(123) == int
True
>>> type("ABC") == str
True
>>> type([1,2,3]) == list
True
>>> type(("A",1,{1,2})) == tuple
True
>>> type({1,2,3}) == set
True
>>> type({"A":1, "B":2}) == dict
True
[link] B.7. Common Python definition and control constructs (i.e., Python statements)
A Python program is a sequence of Python statements. Each statement is either a function definition, a variable assignment, a conditional statement (i.e.,if, else, and/or elif), an iteration construct (i.e., a for or while loop), a return statement, or a break or continue statement.-
Variable assignments make it possible to assign a value or object to a variable.
It is also possible to assign a tuple (or any computation that produces a tuple) to another tuple:
x = 10
(x, y) = (1, 2)
-
Function and procedure definitions consist of the
defkeyword, followed by the name of the function or procedure, and then by one or more arguments (delimited by parentheses and separated by commas).
def example(a, b, c):
return a + b + c
-
Conditional statements consist of one or more branches, each with its own boolean expression as the condition (with the exception of
else). The body of each branch is an indented sequence of statements.
def fibonacci(n):
# Computes the nth Fibonacci number.
if n <= 0:
return 0
elif n <= 2:
return 1
else:
return fibonacci(n-1) + fibonacci(n-2)
-
Iteration constructs make it possible to repeat a sequence of statements over and over. The body of an iteration construct is an indented sequence of statements.
-
The while construct has a boolean expression as its condition (much like
if). The body is executed over and over until the expression in the condition evaluates toFalse, or abreakstatement is encountered.
def example1(n):
# Takes an integer n and returns the sum of
# the integers from 1 to n-1.
i = 0
sum = 0
while i < n:
sum = sum + i
i = i + 1
return sum
def example2(n):
# Takes an integer n and returns the sum of
# the integers from 1 to n-1.
i = 0
sum = 0
while True:
sum = sum + i
i = i + 1
if i == n:
break
return sum
-
The for construct makes it possible to repeat a sequence of statements once for every object in a list, tuple, or set, or once for every key in a dictionary.
def example3(n):
# Takes an integer n and returns the sum of
# the integers from 1 to n-1.
sum = 0
for i in range(0,n):
sum = sum + i
return sum
def example4(d):
# Takes a dictionary d that maps keys to
# integers and returns the sum of the integers.
sum = 0
for key in d:
sum = sum + d[key]
return sum
-
The while construct has a boolean expression as its condition (much like